《从零开始构建智能体》第三章 大语言模型基础-读书笔记
语言模型 (Language Model, LM) 是自然语言处理的核心,其根本任务是计算一个词序列(即一个句子)出现的概率。一个好的语言模型能够告诉我们什么样的句子是通顺的、自然的。
在多智能体系统中,语言模型是智能体理解人类指令、生成回应的基础。
📝 LLM发展阶梯
LLM发展的四个层级,每一层都代表了语言模型发展的一次重要飞跃:
第一级:N-gram 模型
- 能做什么:建立了统计语言模型的基本范式,计算简单快速,结果可解释。
- 核心思想:马尔可夫假设。
- 局限:不懂语义,泛化能力差,且受限于固定窗口。
第二级:前馈神经网络语言模型
- 能做什么:通过词嵌入,让模型能理解词之间的语义相似性,大大增强了泛化能力。
- 核心思想:将词映射为连续向量。
- 局限:上下文窗口仍然是固定的,无法处理更长的历史信息。
第三级:循环神经网络 (RNN/LSTM)
- 能做什么:通过循环结构,理论上能处理任意长度的序列,拥有了“记忆”。LSTM 进一步缓解了长距离依赖问题。
- 核心思想:信息在序列中循环传递。
- 局限:循环计算是串行的,无法并行,训练效率低,且长距离依赖问题依然存在挑战。
第四级:Transformer 与大模型
- 能做什么:完全基于自注意力机制,实现了高效并行计算,并能直接捕捉序列中任意长距离的依赖关系,成为现代大语言模型的基础。
- 核心思想:自注意力。
- 局限:目前主要挑战在于计算成本高昂、推理时的显存占用等。
N-gram 模型的根本缺陷在于它将词视为孤立、离散的符号。
为了克服这个问题,研究者们转向了神经网络,并提出了一种思想:用连续的向量来表示词。
2003年,Bengio 等人提出的前馈神经网络语言模型 (Feedforward Neural Network Language Model) 是这一领域的里程碑。
其核心思想可以分为两步:
- 构建一个语义空间:创建一个高维的连续向量空间,然后将词汇表中的每个词都映射为该空间中的一个点。这个点(即向量)就被称为词嵌入 (Word Embedding) 或词向量。在这个空间里,语义上相近的词,它们对应的向量在空间中的位置也相近。例如,
agent和robot的向量会靠得很近,而agent和apple的向量会离得很远。 - 学习从上下文到下一个词的映射:利用神经网络的强大拟合能力,来学习一个函数。这个函数的输入是前 n−1 个词的词向量,输出是词汇表中每个词在当前上下文后出现的概率分布。
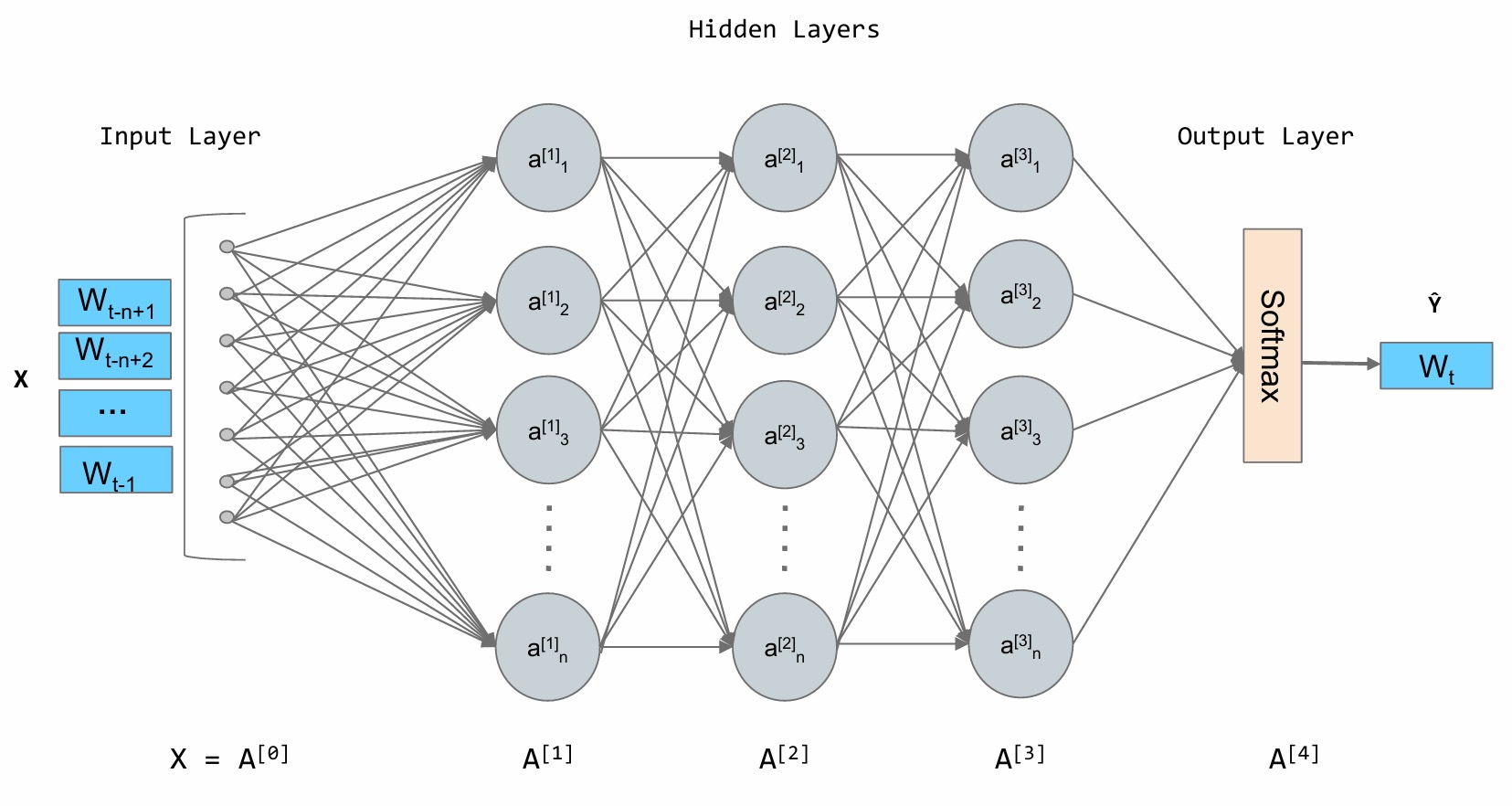
在这个架构中,词嵌入是在模型训练过程中自动学习得到的。
模型为了完成“预测下一个词”这个任务,会不断调整每个词的向量位置,最终使这些向量能够蕴含丰富的语义信息。一旦我们将词转换成了向量,我们就可以用数学工具来度量它们之间的关系。
最常用的方法是余弦相似度 (Cosine Similarity) ,它通过计算两个向量夹角的余弦值来衡量它们的相似性。
- 如果两个向量方向完全相同,夹角为0°,余弦值为1,表示完全相关。
- 如果两个向量方向正交,夹角为90°,余弦值为0,表示毫无关系。
- 如果两个向量方向完全相反,夹角为180°,余弦值为-1,表示完全负相关。
通过这种方式,词向量不仅能捕捉到“同义词”这类简单的关系,还能捕捉到更复杂的类比关系。
一个著名的例子展示了词向量捕捉到的语义关系: vector('King') - vector('Man') + vector('Woman') 这个向量运算的结果,在向量空间中与 vector('Queen') 的位置惊人地接近。
这好比在进行语义的平移:我们从“国王”这个点出发,减去“男性”的向量,再加上“女性”的向量,最终就抵达了“女王”的位置。这证明了词嵌入能够学习到“性别”、“皇室”这类抽象概念。
神经网络语言模型通过词嵌入,成功解决了 N-gram 模型的泛化能力差的问题。
然而,它仍然有一个类似 N-gram 的限制:上下文窗口是固定的。
它只能考虑固定数量的前文,这为能处理任意长序列的循环神经网络埋下了伏笔。
📊 核心特点对比
| 特点 | N-gram 模型 | 前馈神经网络语言模型 |
|---|---|---|
| 核心机制 | 基于计数和马尔可夫假设 | 基于神经网络和词嵌入 |
| 词表示 | 离散符号,无语义关系 | 连续向量,语义相近则向量相近 |
| 泛化能力 | 弱,没见过的词对直接判零 | 强,可迁移到相似词语 |
| 上下文 | 固定窗口 | 固定窗口 |
| 主要贡献 | 奠基 | 引入词嵌入,解决语义泛化问题 |
🔗 演进链中的位置:承上启下
理解这个模型在演进史中的位置,能帮你更清晰地把握脉络:
- 相比N-gram:最大的进步是解决了语义鸿沟。N-gram看到“猫 吃 三文鱼”会不知所措,因为没数到过“吃 三文鱼”;但前馈神经网络语言模型从“猫 吃 鱼”里学过“吃”和“鱼”的向量关系,能类推到“三文鱼”。
- 它的局限:和N-gram一样,它的上下文窗口仍然是固定的(比如只能看前面3个词)。更早的信息会被截断,无法利用。这个“记不远”的局限,直接催生了后续能处理任意长度序列的循环神经网络(RNN)。
💎 总结
“前馈神经网络语言模型”的核心贡献,可以总结为三点:
- 开创了“词嵌入”:让计算机能用向量表示词语的语义,这是现代NLP的基石。
- 解决了核心痛点:通过词嵌入,有效克服了N-gram模型泛化能力差的致命缺陷。
- 指明了演进方向:它暴露了“固定上下文窗口”的瓶颈,为RNN等能处理长距离依赖的模型铺平了道路。
可以说,它是从“统计语言模型”迈向“现代大语言模型”的第一块重要基石。理解它,能帮你更深刻地体会到“词向量”这项基础技术的革命性意义。