《从零开始构建智能体》第三章 大语言模型基础-读书笔记
语言模型 (Language Model, LM) 是自然语言处理的核心,其根本任务是计算一个词序列(即一个句子)出现的概率。一个好的语言模型能够告诉我们什么样的句子是通顺的、自然的。
在多智能体系统中,语言模型是智能体理解人类指令、生成回应的基础。
📝 LLM发展阶梯
LLM发展的四个层级,每一层都代表了语言模型发展的一次重要飞跃:
第一级:N-gram 模型
- 能做什么:建立了统计语言模型的基本范式,计算简单快速,结果可解释。
- 核心思想:马尔可夫假设。
- 局限:不懂语义,泛化能力差,且受限于固定窗口。
第二级:前馈神经网络语言模型
- 能做什么:通过词嵌入,让模型能理解词之间的语义相似性,大大增强了泛化能力。
- 核心思想:将词映射为连续向量。
- 局限:上下文窗口仍然是固定的,无法处理更长的历史信息。
第三级:循环神经网络 (RNN/LSTM)
- 能做什么:通过循环结构,理论上能处理任意长度的序列,拥有了“记忆”。LSTM 进一步缓解了长距离依赖问题。
- 核心思想:信息在序列中循环传递。
- 局限:循环计算是串行的,无法并行,训练效率低,且长距离依赖问题依然存在挑战。
第四级:Transformer 与大模型
- 能做什么:完全基于自注意力机制,实现了高效并行计算,并能直接捕捉序列中任意长距离的依赖关系,成为现代大语言模型的基础。
- 核心思想:自注意力。
- 局限:目前主要挑战在于计算成本高昂、推理时的显存占用等。
神经网络语言模型虽然引入了词嵌入解决了泛化问题,但它和 N-gram 模型一样,上下文窗口是固定大小的。为了预测下一个词,它只能看到前 n−1 个词,再早的历史信息就被丢弃了。这显然不符合我们人类理解语言的方式。为了打破固定窗口的限制,循环神经网络 (Recurrent Neural Network, RNN) 应运而生,其核心思想非常直观:为网络增加“记忆”能力。
RNN 的设计引入了一个隐藏状态 (hidden state) 向量,我们可以将其理解为网络的短期记忆。在处理序列的每一步,网络都会读取当前的输入词,并结合它上一刻的记忆(即上一个时间步的隐藏状态),然后生成一个新的记忆(即当前时间步的隐藏状态)传递给下一刻。这个循环往复的过程,使得信息可以在序列中不断向后传递
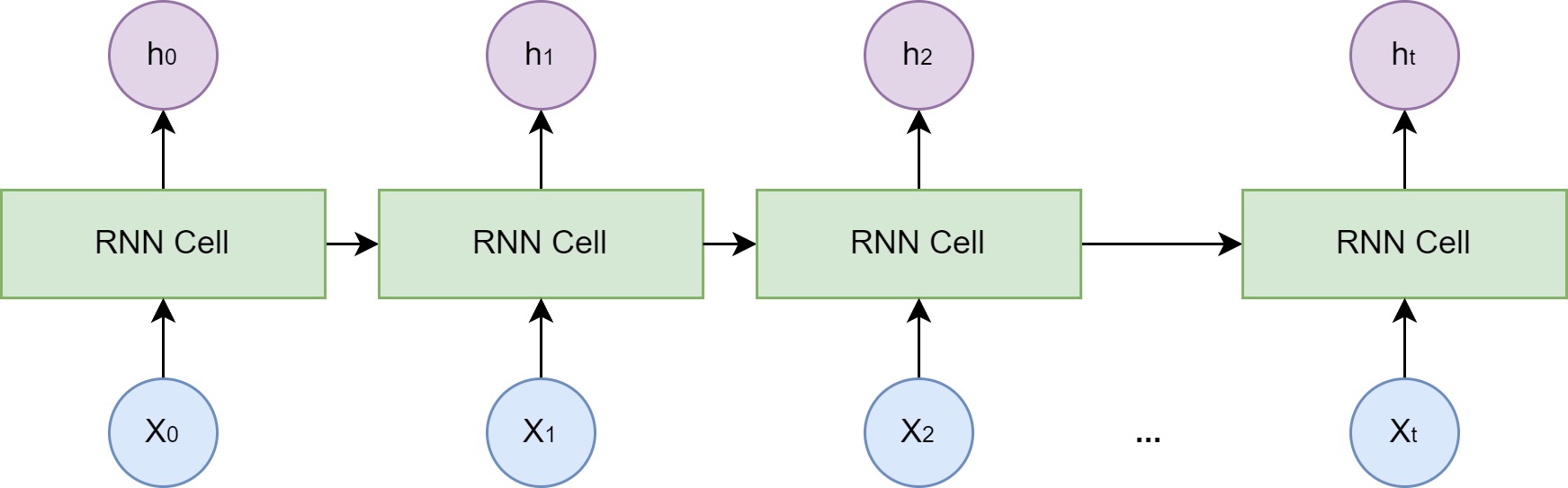
🧠 RNN 的核心:一个携带“记忆”的处理器
可以把RNN想象成一个有“短期记忆”的处理器。它处理信息的方式不是孤立的,而是会把对之前信息的“记忆”带到下一步的计算中。
它的工作流程就像一个“接力”过程:
- 读取当前输入:在每一步
t,它都会读取当前的输入信息x_t(例如,句子中的第t个词)。 - 结合历史记忆:它会调出上一步结束时留下的“记忆”,也就是上一个隐藏状态
h_{t-1}。 - 更新记忆:然后,它通过一个函数(可以理解为“思考”过程),把“当前输入”和“历史记忆”整合起来,形成新的记忆
h_t。 - 传递与输出:这个新的记忆
h_t有两个用途:一是作为这一步的“思考结果”输出(如果需要的话),二是被传递到下一步,作为下一步的“历史记忆”。
这个过程用公式简化表示就是:h_t = f( x_t, h_{t-1} )。这个循环机制,正是RNN能处理任意长度序列的关键。
📝 生动例子:理解带“上文”的句子
为了让你更直观地感受RNN的作用,我们用一个具体的句子来模拟它的处理过程。假设我们要让RNN处理下面这句话:
我 喜欢 吃 苹果
- 处理
我:RNN读取“我”。此时它没有历史记忆(或记忆为空),结合“我”和空记忆,形成新的记忆h1,这个h1就编码了“我”这个信息。 - 处理
喜欢:RNN读取“喜欢”,并调出上一步的h1(即“我”的信息)。它把“喜欢”和“我”结合起来思考,更新记忆为h2。此时的h2就包含了“我”和“喜欢”的上下文信息。 - 处理
吃:RNN读取“吃”,并调出上一步的h2(即“我 喜欢”的上下文)。它把“吃”和“我 喜欢”结合,更新记忆为h3。此时h3包含了“我 喜欢 吃”的信息。 - 处理
苹果:RNN读取“苹果”,并调出h3(即“我 喜欢 吃”的上下文)。它结合后形成h4,最终h4就完整地编码了整个句子“我 喜欢吃 苹果”的语义信息。
你看,通过这种“边读边记”的方式,RNN在处理最后一个词“苹果”时,依然清楚地记得句子开头的“我”,理解了是“我”在“吃”。这正是RNN能处理序列、捕捉上下文的关键。
🔍 与之前模型的对比
把RNN和前两代模型放在一起看,它的优势就更清楚了:
| 模型 | 核心机制 | 对“我 喜欢 吃 苹果”的处理方式 | 关键局限 |
|---|---|---|---|
| N-gram | 固定窗口,只看前 N-1 个词 | 预测“吃”后面的词时,只能看到“喜欢 吃”或“吃”,看不到开头的“我”。 | 无法捕捉长距离依赖 |
| 前馈神经网络语言模型 | 词嵌入 + 固定窗口 | 比N-gram理解语义,但窗口依然固定,看“吃”时仍然可能漏掉“我”。 | 无法处理不定长序列 |
| RNN / LSTM | 循环连接 + 隐藏状态 | 通过隐藏状态 h,把“我”的信息一步步传到“吃”和“苹果”,实现了对全句的“记忆”。 |
串行计算,效率较低;简单RNN有梯度问题 |
⚠️ RNN 的局限性
虽然RNN很巧妙,但它也有明显的短板,这直接催生了Transformer:
- 串行计算:必须一个一个词地处理,第
t步没算完,就不能开始t+1步。这导致训练无法充分利用GPU进行大规模并行计算,速度很慢。 - 长期依赖问题:简单RNN在实践中很难记住非常久远的信息(比如几十个词之前的主语),因为信息在循环传递中会“衰减”。
💎 总结
RNN通过引入隐藏状态和循环连接,实现了对序列信息的“记忆”和传递,成功突破了前代模型固定窗口的限制,能够处理任意长度的序列。这个设计在自然语言处理领域是里程碑式的。
尽管它因为串行计算和长期依赖问题,在后来被Transformer架构取代了主流地位,但它所蕴含的“让模型拥有记忆”的核心思想,至今仍在深刻影响着现代大语言模型的设计。