《从零开始构建智能体》第三章 大语言模型基础-读书笔记
语言模型 (Language Model, LM) 是自然语言处理的核心,其根本任务是计算一个词序列(即一个句子)出现的概率。一个好的语言模型能够告诉我们什么样的句子是通顺的、自然的。
在多智能体系统中,语言模型是智能体理解人类指令、生成回应的基础。
最初的 Transformer 模型是为端到端任务机器翻译而设计的。如图所示,它在宏观上遵循了一个经典的编码器-解码器 (Encoder-Decoder) 架构。
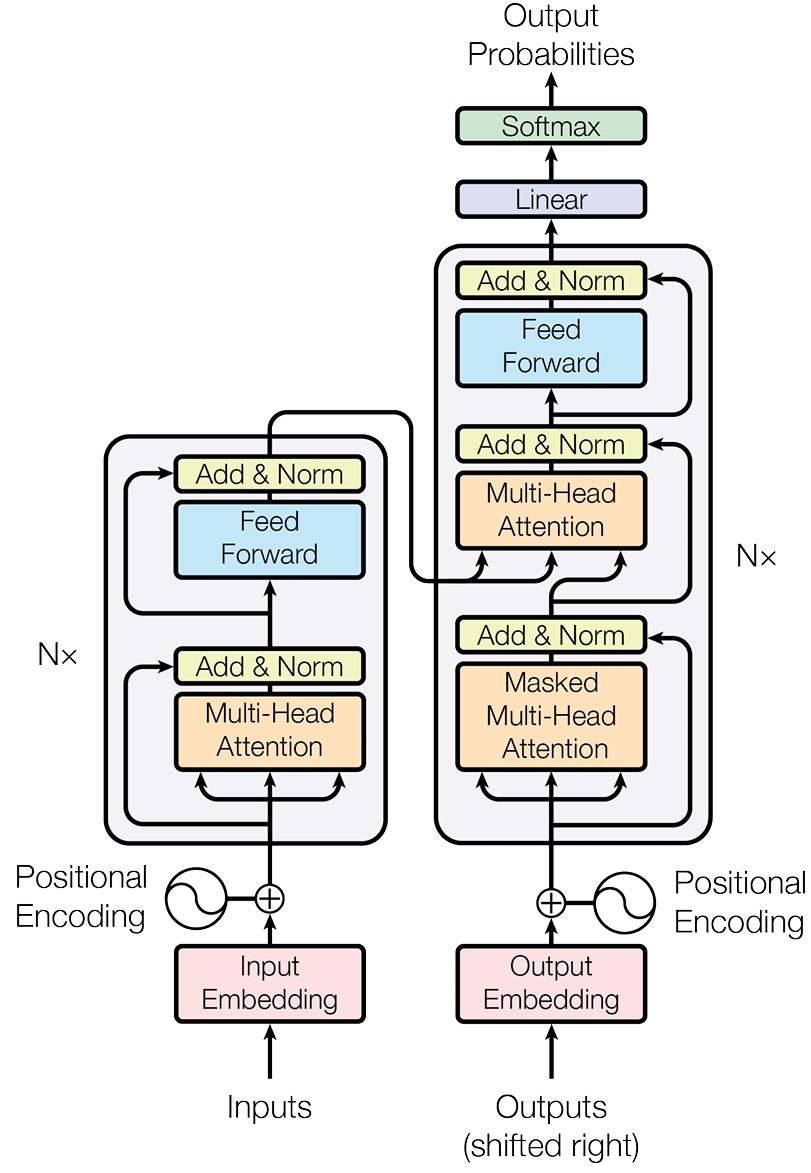
Transformer 是一种在自然语言处理(NLP)领域极具影响力的深度学习模型架构,最初由 Google 团队在 2017 年的论文《Attention Is All You Need》中提出。它彻底改变了 NLP 领域,成为了后来 BERT、GPT 等著名模型的基础。
以下是对图中各个部分的详细解析:
整体结构
该架构主要分为两大部分:
- 编码器 (Encoder) :任务是“理解”输入的整个句子。它会读取所有输入词元,最终为每个词元生成一个富含上下文信息的向量表示。
- 解码器 (Decoder) :任务是“生成”目标句子。它会参考自己已经生成的前文,并“咨询”编码器的理解结果,来生成下一个词。
这是一个典型的“编码器-解码器”架构,常用于机器翻译等序列到序列(Seq2Seq)的任务。
1. 输入部分 (Input)
- Inputs (输入):这是模型的原始输入序列(例如一句话中的单词)。
- Input Embedding (输入嵌入):将离散的单词索引转换为连续的向量表示,以便模型处理。
- Positional Encoding (位置编码):因为 Transformer 不像循环神经网络(RNN)那样按顺序处理数据,它本身没有“顺序”的概念。位置编码被加到嵌入向量中,用来告诉模型单词在句子中的位置信息。
2. 编码器 (Encoder) - 左侧堆叠部分
编码器由 $N$ 个相同的层堆叠而成(图中的 $N\times$ 表示重复 $N$ 次,原论文中 $N=6$)。每一层包含两个主要子层:
- 多头注意力机制 (Multi-Head Attention):这是 Transformer 的核心。它允许模型在处理一个词时,“关注”输入序列中的其他词。多头意味着模型会在不同的表示子空间中并行地执行多次注意力机制,从而捕捉更丰富的信息。
- 前馈神经网络 (Feed Forward):这是一个简单的全连接层,对每个位置的向量进行相同的线性变换和激活函数处理。
- Add & Norm (残差连接与层归一化):在每个子层周围都有残差连接(箭头绕过子层直接相加),然后进行层归一化。这有助于训练深层网络,防止梯度消失。
3. 解码器 (Decoder) - 右侧堆叠部分
解码器同样由 $N$ 个相同的层堆叠而成。每一层包含三个主要子层:
- 掩码多头注意力机制 (Masked Multi-Head Attention):这与编码器中的注意力机制类似,但增加了一个“掩码”。这是为了在训练时防止模型在预测当前位置的词时“偷看”后面的词(即未来的信息)。
- 多头注意力机制 (Multi-Head Attention):这一层接收来自解码器上一层的输出,以及来自编码器最终输出的信息。它让解码器能够关注输入序列中的相关部分(例如在翻译时关注源语言句子中的对应单词)。
- 前馈神经网络 (Feed Forward):与编码器中的结构相同。
- 同样,每个子层周围也有 Add & Norm。
4. 输出部分 (Output)
- Linear (线性层):解码器的输出经过一个线性变换(全连接层),将向量映射到一个高维空间,其维度等于词汇表的大小。
- Softmax:将线性层的输出转换为概率分布。每个值代表对应词汇表中单词被选为下一个输出词的概率。
- Output Probabilities (输出概率):最终模型预测的下一个词的概率。
总结
这张图清晰地展示了 Transformer 如何利用 自注意力机制 (Self-Attention) 来并行处理数据,从而比传统的 RNN/LSTM 模型训练速度更快,且能更好地捕捉长距离依赖关系。