《DDD之形》把当前一些流行的架构给通览了一篇,那是不是万事大吉,随便挑一个形态实践就行呢?
正常情况对于有追求的程序员来讲,肯定不行,有两个原因
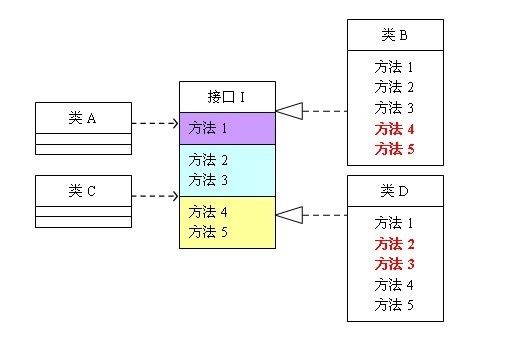
一因为完美,人人都是想要完美,每个架构实践都不是完美的,尤其离开业务场景去探讨架构,会使架构没法落地;因此你小抄的时候会变形,想把原先至少不太好的地方改得相对好些,但这样可能造成四不像
二因为没有意的形,只知其形,不得其意,必然会东施效颦;类似于第一点,完美,何为完美,还是得根据自身经验理解程序得出的结论,如果高度不够必然会画蛇添足
标准形态
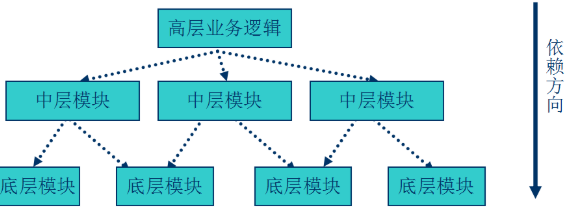
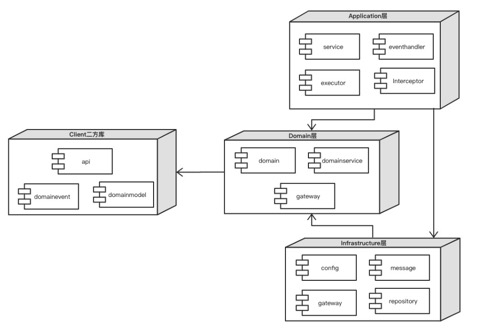
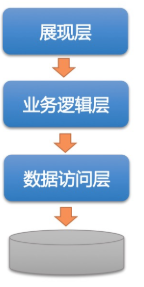
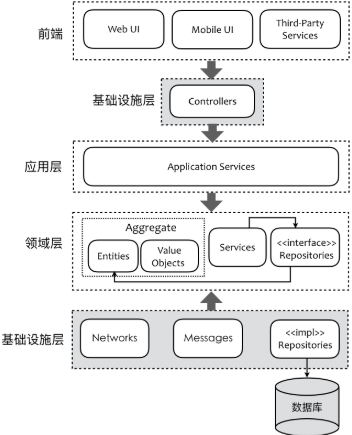
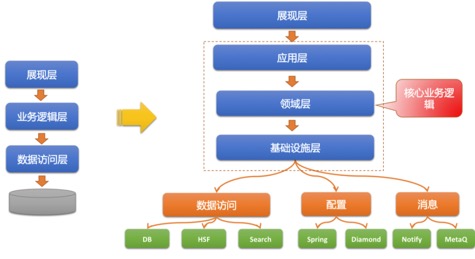
根据DDD的理论,或者说DDD带来的优势,将三层架构进行演化,把业务逻辑层再细拆分成三层:应用层、领域层和基础设施层
分离业务逻辑与技术细节
DDD的标准形态
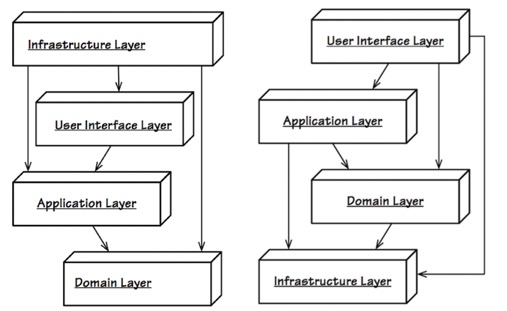
分层架构分为两种:严格分层架构和松散分层架构
严格分层,某层只能与直接位于其下方的层发生耦合;松散分层,允许任意上方层与任意下方层发生耦合
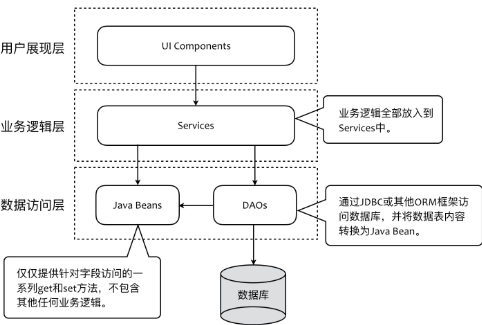
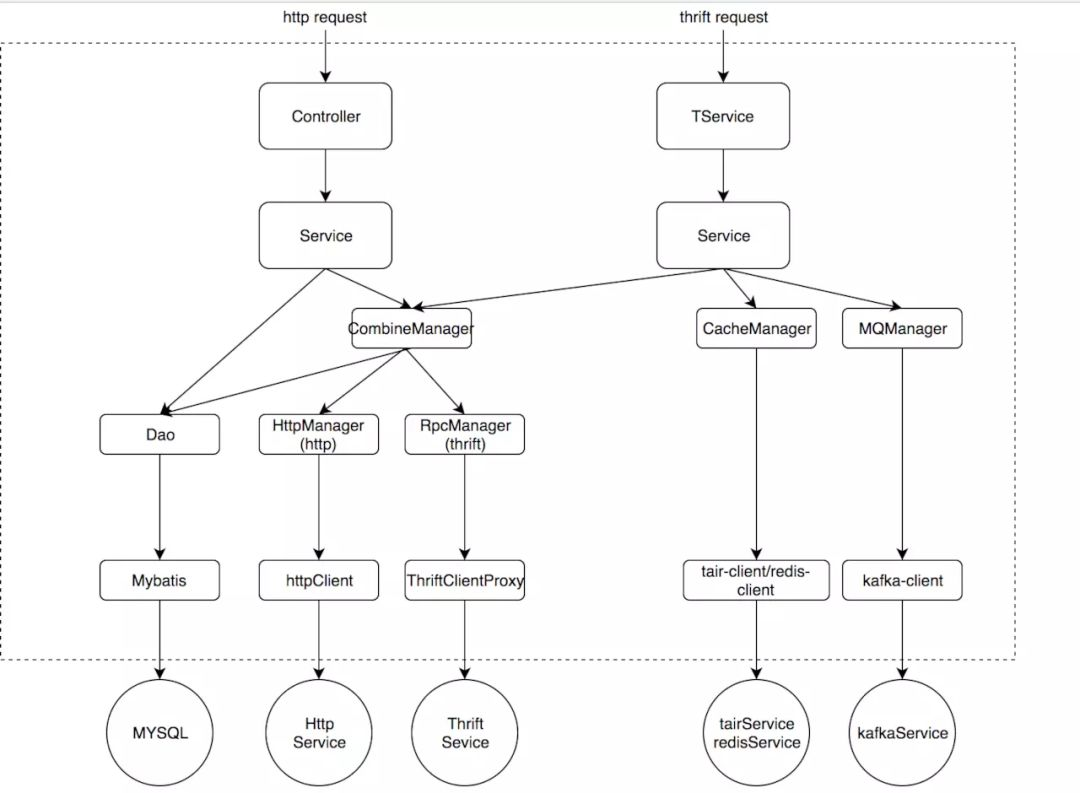
- User Interface是用户接口层,主要用于处理用户发送的Restful请求和解析用户输入的配置文件等,并将信息传递给Application层的接口
- Application层是应用层,负责多进程管理及调度、多线程管理及调度、多协程调度和维护业务实例的状态模型。当调度层收到用户接口层的请求后,委托Context层与本次业务相关的上下文进行处理
- Domain层是领域层,定义领域模型,不仅包括领域对象及其之间关系的建模,还包括对象的角色role的显式建模
- Infrastructure层是基础实施层,为其他层提供通用的技术能力:业务平台,编程框架,持久化机制,消息机制,第三方库的封装,通用算法,等等
DIP
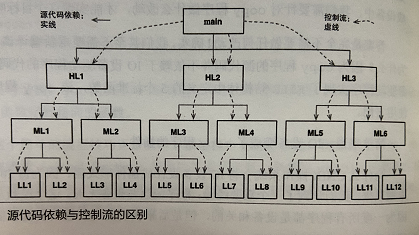
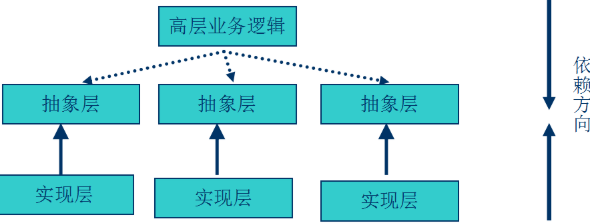
上面的标准形态图形的左半边图,跟以往的很不一样,但从DIP角度看,低层服务应该依赖于高层组件
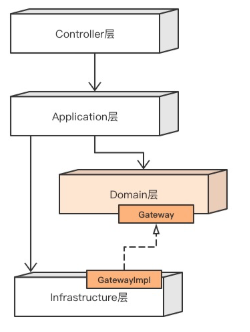
这是COLA2.0的分层,作者利用DIP对1.0版本进行了优化
1、核心业务逻辑和技术细节相分离,使用DIP,让Infrastructure反向依赖Domain
2、将repository上移到application层,把组装entity的责任转移到application
到此一切都很常规,很标准,但在落地时有几个问题:
一、Controller是哪一层,user interface层?还是infrastructure层?
这好像不是个问题,一般都放在user interface层,负责向用户展现信息以及解释用户命令;但细想一下,我们的controller都是基于底层框架,是框架提供的能力,那理论上放在infrastructure更合理一些。
二、再细化的架构元素放哪里?
其实这只是分层的大体方向,还有更细节的元素,在实践DDD的过程中,最常见的问题就是元素到底放在哪儿,比如Event,有各样的event,eventHandler,应用层、领域层都有,怎么区分呢?貌似回到了怎么区分应用服务与领域服务;还有各处javabean,哪些层能复用,谁复用谁
再比如COLA2.0,单从层次依赖图明显形成了循环依赖,落地不了;但作者把repository上移到了application层,又有些走不寻常路,一般来讲repository是放在domain层
如何办呢?大方向有了,但到小细节时,又有各种困惑,《SOLID之DIP》文中提到,分层至少有两层,一是业务领域层,二是其它层

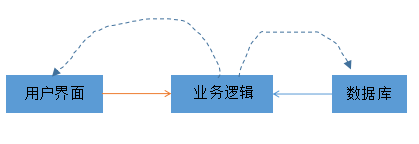
这就是端口和适配器架构,可以算是六边形的简化版,但也从整体方向分成了两层,对应用层与用户接口层以及基础设施层进行了合并,无论是接受请求,还是输出数据都是gateway
但六边形架构仅仅区分了内外边界,提炼了端口与适配器角色,并没有规划限界上下文内部各个层次与各个对象之间的关系;怎么破?
这似乎是两个矛盾体,标准的层次分明了,但还是有些不确定性,对象放在哪个包不明确;而端口与适配器架构又太粗放;如何平衡?
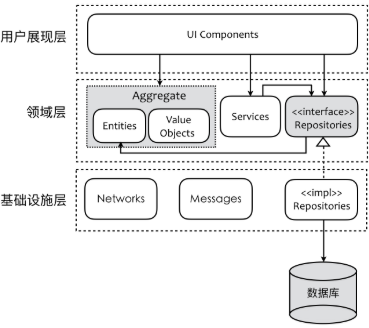
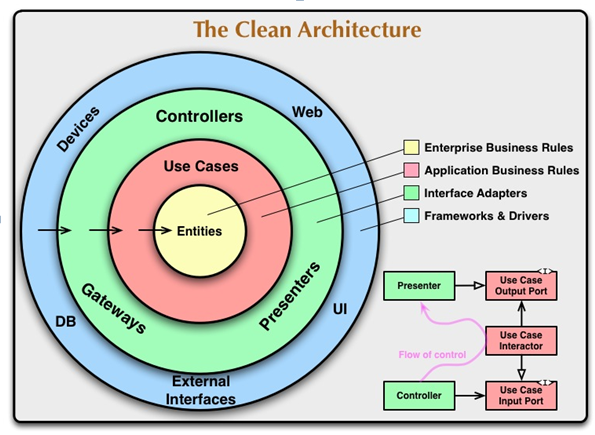
本质上,领域驱动设计的限界上下文同样是对软件系统的切割,依据的关注点主要是根据领域知识的语境,从而体现业务能力的差异。在进入限界上下文内部,我们又可以针对限界上下文进行关注点的切割,并在其内部体现出清晰的层次结构,这个层次遵循整洁架构
根据张逸老师DDD课程中的案例
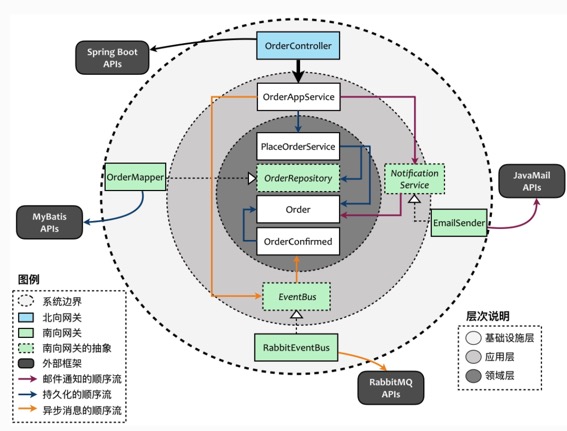
- 领域层:包含 PlaceOrderService、Order、Notification、OrderConfirmed 与抽象的 OrderRepository,封装了纯粹的业务逻辑,不掺杂任何与业务无关的技术实现。
- 应用层:包含 OrderAppService 以及抽象的 EventBus 与 NotificationService,提供对外体现业务价值的统一接口,同时还包含了基础设施功能的抽象接口。
- 基础设施层:包含 OrderMapper、RabbitEventBus 与 EmailSender,为业务实现提供对应的技术功能支撑,但真正的基础设施访问则委派给系统边界之外的外部框架或驱动器
重新审视六边形架构,匹配分层架构,两者可以融合
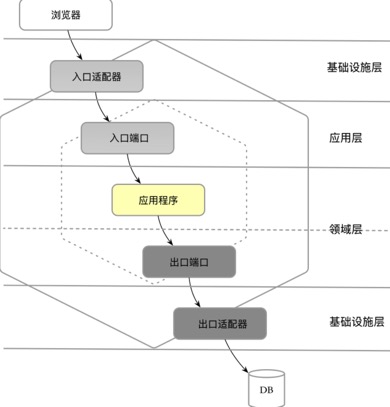
位于六边形边线之上的出口端口就应该既不属于领域层,又不属于基础设施层。它的职责与属于应用层的入口端口也不同,因为应用层的应用服务是对外部请求的封装,相当于是一个业务用例的外观
DDD引入repository放在了领域层,一是对应聚合根的概念,二是抽象了数据库访问,,但DDD限界上下文可能不仅限于访问数据库,还可能访问同样属于外部设备的文件、网络与消息队列。为了隔离领域模型与外部设备,同样需要为它们定义抽象的出口端口,这些出口端口该放在哪里呢?如果依然放在领域层,就很难自圆其说。例如,出口端口EventPublisher支持将事件消息发布到消息队列,要将这样的接口放在领域层,就显得不伦不类了。倘若不放在位于内部核心的领域层,就只能放在领域层外部,这又违背了整洁架构思想