《从零开始构建智能体》第三章 大语言模型基础-读书笔记
语言模型 (Language Model, LM) 是自然语言处理的核心,其根本任务是计算一个词序列(即一个句子)出现的概率。一个好的语言模型能够告诉我们什么样的句子是通顺的、自然的。
在多智能体系统中,语言模型是智能体理解人类指令、生成回应的基础。
在深度学习兴起之前,统计方法是语言模型的主流
其核心思想是,一个句子出现的概率,等于该句子中每个词出现的条件概率的连乘。
对于一个由词 w1,w2,⋯,wm 构成的句子 S,其概率 P(S) 可以表示为:
P(S)=P(w1,w2,…,wm)=P(w1)⋅P(w2∣w1)⋅P(w3∣w1,w2)⋯P(wm∣w1,…,wm−1)
这个公式被称为概率的链式法则。
然而,直接计算这个公式几乎是不可能的,
因为像 P(wm∣w1,⋯,wm−1) 这样的条件概率太难从语料库中估计了,
词序列 w1,⋯,wm−1 可能从未在训练数据中出现过
这个公式的意义在于,它将一个极其复杂的问题(一个句子有无数种可能),变成了一个简单、可计算的重复问题(下一个词是什么?)。
公式说明
P(w_2|w_1) 是概率论和自然语言处理中一个非常核心的符号。它表示条件概率。
你可以把它读作:“在给定第一个词是 w_1 的条件下,第二个词是 w_2 的概率”。
用最直白的方式来解释:
想象你在和朋友玩一个“猜下一个词”的游戏。朋友已经说了第一个词“喜欢”,现在要你来猜下一个词是什么。
P(吃 | 喜欢)的意思是:在朋友说了“喜欢”之后,你猜下一个词是“吃”的概率有多大?- 如果平时大家常说“喜欢 吃苹果”、“喜欢 吃披萨”,那你猜“吃”的概率就会很高,比如 0.4。
P(游泳 | 喜欢)的意思是:在“喜欢”之后,你猜下一个词是“游泳”的概率有多大?- 大家也常说“喜欢 游泳”、“喜欢 跑步”,那这个概率可能也不错,比如 0.3。
P(桌子 | 喜欢)的意思是:在“喜欢”之后,你猜下一个词是“桌子”的概率有多大?- 我们几乎不说“喜欢 桌子”,那你猜“桌子”的概率就会非常非常低,比如 0.0001。
这个概率值,完全取决于我们从大量的文本(语料库)中统计出来的“习惯”。
句子:“今天 天气 真好”
根据链式法则,它的概率可以拆解为:
P(今天): “今天”这个词作为句子开头的概率。P(天气 | 今天): 在已经看到“今天”的情况下,下一个词是“天气”的概率。P(真好 | 今天, 天气): 在已经看到“今天 天气”的情况下,下一个词是“真好”的概率。
最后,把这个概率乘起来:P(今天 天气 真好) = P(今天) × P(天气|今天) × P(真好|今天, 天气)
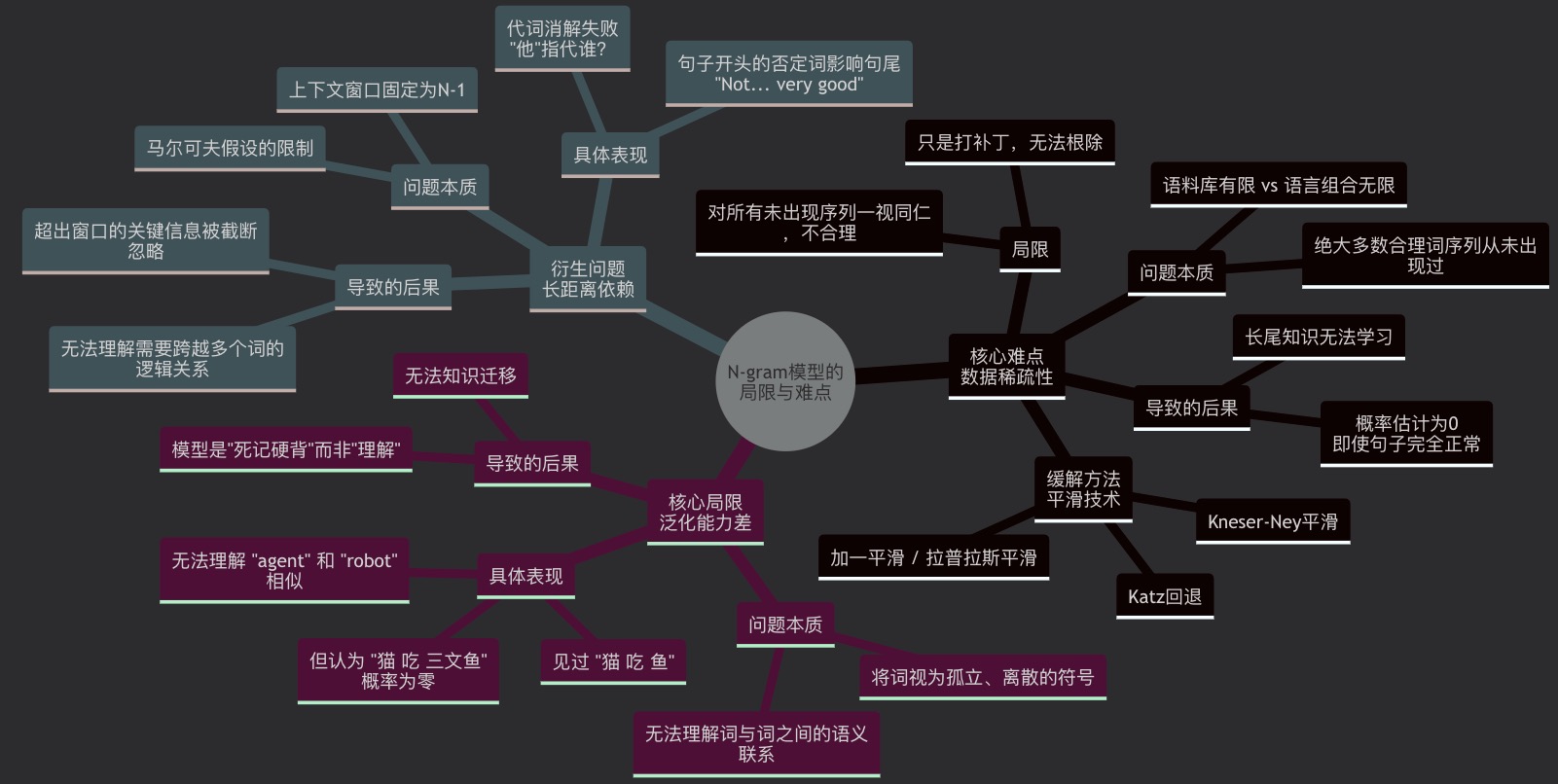
数据稀疏:这是最致命的问题。
由于语言组合无穷,任何合理的词序列(如“吃 耳机”)都可能从未在语料库中出现过,导致其概率为0。
虽然可用平滑技术打个“补丁”,但无法根治。
理论上,要准确计算 P(学习 | 我, 喜欢, 在, 图书馆),我们需要在语料库中看到无数次“我 喜欢 在 图书馆 学习”这个5词序列。
但现实是,即便语料库有百亿词,绝大多数长序列也一次都不会出现。
那么 Count(我, 喜欢, 在, 图书馆, 学习) 就等于0,导致整个句子的概率被判为0。
这显然不合理。
理论上公式很完美,但现实中,词序列 (w₁, ..., wₘ₋₁) 的组合是天文数字,几乎不可能出现完全一样的。所以,直接计算这个概率是不可能的。
马尔可夫假设
为了解决这个问题,研究者们提出了马尔可夫假设,简化成 N-gram 模型:
“一个词出现的概率,只取决于它前面的 N-1 个词,而不是整个历史。”
Unigram (1-gram):
P(wₘ),忽略所有历史,词与词之间独立。这几乎不能称为一个“句子”。Bigram (2-gram):
P(wₘ | wₘ₋₁),只考虑前一个词。例如,P(真好 | 天气)。Trigram (3-gram):
P(wₘ | wₘ₋₂, wₘ₋₁),只考虑前两个词。
现代的大语言模型(如GPT系列)可以看作是一个超级复杂、规模巨大的N-gram模型,它能高效地估算出非常长距离的上下文条件概率,从而生成流畅、连贯的文本。
基于这个原理,N-gram 模型的优缺点都非常鲜明。
优点:简单、快速、可解释
原理简单,计算高效:模型的核心就是统计和查表,训练时只需遍历语料库统计词频,运行时通过查表和简单乘法就能算出概率,计算量很小。
结果完全可解释:模型为什么算出某个概率是透明的。例如,
P(吃|喜欢)的概率高,可以直接追溯到语料库中“喜欢 吃”这对词出现了很多次。这种可解释性在金融、医疗等严谨领域很有价值。在小规模、领域明确的场景下效果不错:对于语法规范、词汇有限的特定领域(如客服查询、日志分析),N-gram 模型依然能提供稳定、快速的基础服务,常被用作基线模型。
缺点:无法处理语言的复杂性和创造性
数据稀疏性:这是最核心的缺陷。即使语料库很大,也总会有合理的 N-gram 序列没出现过。比如,在 Bigram 模型中,没见过的“吃 耳机”概率会直接变成 0,这显然不合理。虽然可以用平滑技术打个“补丁”,给零概率词分一点值,但无法从根本上解决问题。
泛化能力差:模型完全是“死记硬背”,无法理解语义的相似性。比如,它见过“猫 吃 鱼”,但看到“猫 吃 三文鱼”时,如果没出现过“吃 三文鱼”,就会判断其概率为零。它无法将“鱼”和“三文鱼”联系起来,因为模型不知道这两个词在语义上是相似的。
捕捉长距离依赖的能力弱:受限于固定的上下文窗口 N,当 N=2 或 3 时,模型无法处理依赖关系更远的句子。
例子:“我昨天晚上在 Datawhale 的会议上认识了王老师,他**…**”
句末的代词“他”显然指的是“王老师”,但二者之间隔了很多词。在 Bigram 或 Trigram 模型中,预测“他”后面的动词时,根本看不到“王老师”这个信息,很容易预测错误。模型大小随 N 指数增长:N 越大,模型能捕捉的信息越多,但词序列的组合数也会指数级增加。例如,一个含 10万词的词表,Trigram 模型理论上最多需要存储 10^15 个参数,这在实际中是无法接受的。
总的来说,可以把 N-gram 模型的优缺点梳理成下面这张表:
| 维度 | 优点 | 缺点 |
|---|---|---|
| 计算效率 | 训练与预测速度快,资源消耗低 | N 增大时模型参数呈指数级增长 |
| 可解释性 | 决策过程完全透明,易于追溯 | - |
| 语义理解 | - | 泛化能力差,无法理解语义相似性 |
| 上下文处理 | - | 无法捕捉超过 N 的长距离依赖 |
| 数据依赖 | 在小规模、规范领域效果尚可 | 数据稀疏问题严重,大量合理序列概率为零 |
正是为了克服这些缺点,后来的研究者才发展出了神经网络语言模型(如RNN、LSTM),直到现在能处理长距离依赖的Transformer(通过自注意力机制,让一个词可以直接和序列中的任何其他词交互),它们通过引入词嵌入来理解语义,极大地提升了模型的泛化能力。