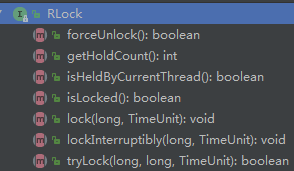
@Override public boolean tryAcquire(int permits, long waitTime, TimeUnit unit) throws InterruptedException { long time = unit.toMillis(waitTime); long current = System.currentTimeMillis();
if (tryAcquire(permits)) { return true; }
time -= (System.currentTimeMillis() - current); if (time <= 0) { return false; }
current = System.currentTimeMillis(); RFuture<RedissonLockEntry> future = subscribe(); if (!await(future, time, TimeUnit.MILLISECONDS)) { return false; }
try { time -= (System.currentTimeMillis() - current); if (time <= 0) { return false; } while (true) { current = System.currentTimeMillis(); if (tryAcquire(permits)) { return true; }
time -= (System.currentTimeMillis() - current); if (time <= 0) { return false; }
// waiting for message current = System.currentTimeMillis();
getEntry().getLatch().tryAcquire(permits, time, TimeUnit.MILLISECONDS);
SET 命令: set key value [EX seconds] [PX milliseconds] [NX|XX] 将字符串值 value 关联到 key 如果 key 已经持有其他值, SET 就覆写旧值,无视类型。 对于某个原本带有生存时间(TTL)的键来说, 当 SET 命令成功在这个键上执行时, 这个键原有的 TTL 将被清除。
可选参数从 Redis 2.6.12 版本开始,SET 命令的行为可以通过一系列参数来修改:
EX second :设置键的过期时间为 second 秒。 SET key value EX second 效果等同于 SETEX key second value
PX millisecond:设置键的过期时间为 millisecond 毫秒。 SET key value PX millisecond 效果等同于 PSETEX key millisecond value
NX :只在键不存在时,才对键进行设置操作。 SET key value NX 效果等同于 SETNX key value
@Override public RFuture<Void> unlockAsync(final long threadId) { final RPromise<Void> result = new RedissonPromise<Void>(); RFuture<Boolean> future = unlockInnerAsync(threadId);
future.addListener(new FutureListener<Boolean>() { @Override public void operationComplete(Future<Boolean> future) throws Exception { if (!future.isSuccess()) { cancelExpirationRenewal(threadId); result.tryFailure(future.cause()); return; }
Boolean opStatus = future.getNow(); if (opStatus == null) { IllegalMonitorStateException cause = new IllegalMonitorStateException("attempt to unlock lock, not locked by current thread by node id: " + id + " thread-id: " + threadId); result.tryFailure(cause); return; } if (opStatus) { cancelExpirationRenewal(null); } result.trySuccess(null); } });
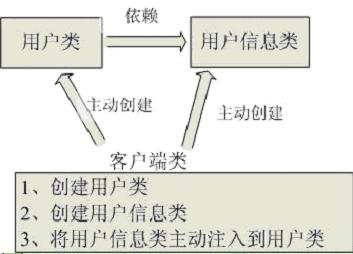
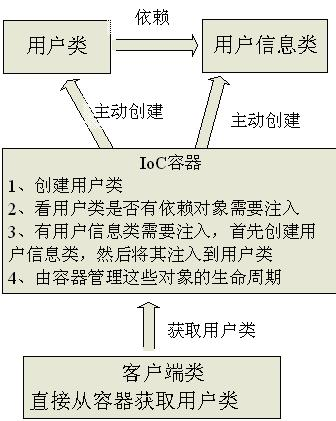
As a result I think we need a more specific name for this pattern. Inversion of Control is too generic a term, and thus people find it confusing. As a result with a lot of discussion with various IoC advocates we settled on the name Dependency Injection.
// 创建一个for 循环,从1 到d for j = 1 to d do int count[10] = {0}; // 将键的计数放在数组count[] 中 // 键key - 是在位数j 上的数字 for i = 0 to n do count[key of(A[i]) in pass j]++ for k = 1 to 10 do count[k] = count[k] + count[k-1] // 创建一个结果数组,通过从count[k] 中检查A[i] 中的新位置 for i = n-1 downto 0 do result[ count[key of(A[i])] ] = A[j] count[key of(A[i])]-- //现在主数组A[] 包含了根据现在位数位置排好序的数字 for i=0 to n do A[i] = result[i] end for(j) end func
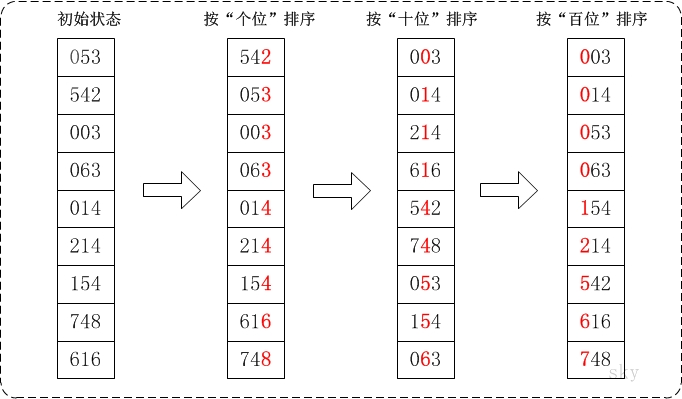
private static void radixSort(int []array){ //取最大值,好计算位数 int max = Integer.MIN_VALUE; for (int a:array) { if(a> max) { max = a; } } //(0~9)10个桶 int [][]buckets = new int[10][];
//初始化桶 for(int b=0;b<10;b++) { buckets[b] = new int[array.length]; }
//每个桶的元素数量 int [] index = new int[10]; //按每一位数排序 for (int radix = 1;max/radix>0;radix*=10){ //把元素放到各自的桶内 for (int a:array) { //得到每位数 int per = a/radix%10; buckets[per][index[per]] = a; index[per]++; } //各个桶的数据依次放回数组 int j = 0; for (int b=0;b<10;b++) { //去掉桶中别的元素 for (int i = 0;i<index[b];i++){ array[j++] = buckets[b][i]; } } System.err.println("按第"+radix+"位,排序:" + Arrays.toString(array)); //清空计数器 index = new int[10]; } }
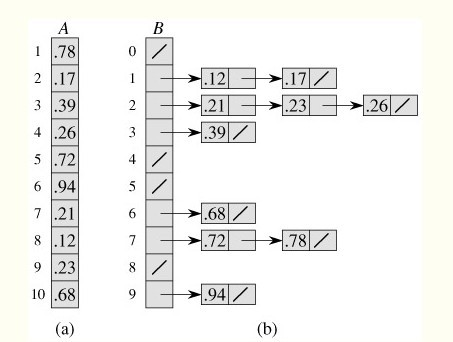
//伪代码 BUCKET_SORT(A) n = length(A) for i= 1 to n do insert A[i] into list B for i=0 to n-1 do sort list B[i] with insertion sort concatenate the list B[0]、B[1],,,B[n-1] together in order
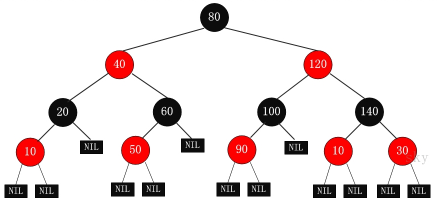
红黑树是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。它是在1972年由Rudolf Bayer发明的,他称之为”对称二叉B树”,它现代的名字是在 Leo J. Guibas 和 Robert Sedgewick 于1978年写的一篇论文中获得的。它是复杂的,但它的操作有着良好的最坏情况运行时间,并且在实践中是高效的: 它可以在O(log n)时间内做查找,插入和删除,这里的n是树中元素的数目
public static long factorial(int n) throws Exception { if (n < 0) throw new Exception("参数不能为负!"); else if (n == 1 || n == 0) return 1; else return n * factorial(n - 1); }
在求解6的阶乘时,递归过程:
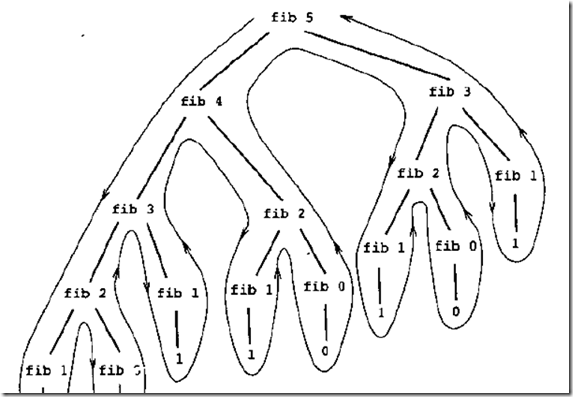
斐波那契数列
斐波那契数列的递推公式:Fib(n)=Fib(n-1)+Fib(n-2),指的是如下所示的数列:
1、1、2、3、5、8、13、21…..
按照其递推公式写出的递归函数如下:
1 2 3 4 5 6 7 8
public static int fib(int n) throws Exception { if (n < 0) throw new Exception("参数不能为负!"); else if (n == 0 || n == 1) return n; else return fib(n - 1) + fib(n - 2); }