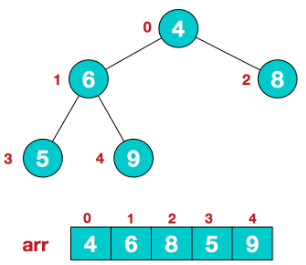
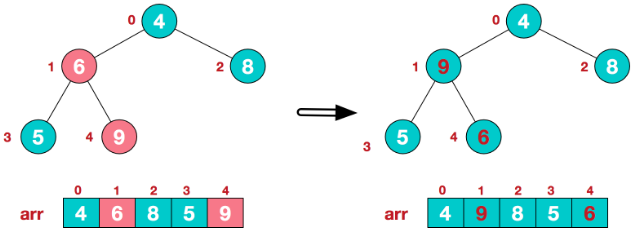
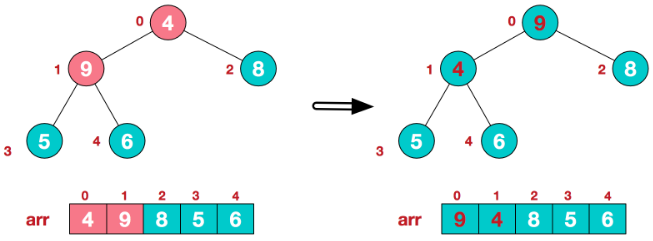
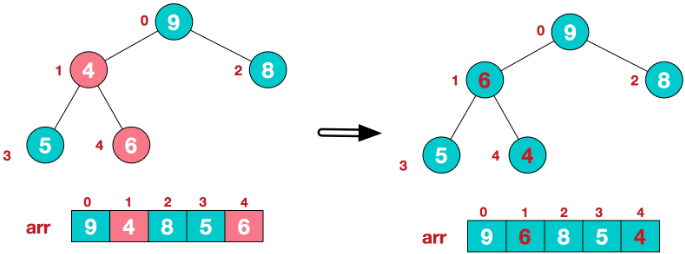
Socket socket = new Socket(); socket.connect(new InetSocketAddress("10.0.0.1",8080),20000);
在timeout时间到时,就会抛出connect timed out异常
1 2 3 4 5 6 7 8 9
Exception in thread "main" java.net.SocketTimeoutException: connect timed out at java.net.DualStackPlainSocketImpl.waitForConnect(Native Method) at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:85) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188) at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:172) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:589)
socketTimeout
Enable/disable SO_TIMEOUT with the specified timeout, in milliseconds. With this option set to a non-zero timeout, a read() call on the InputStream associated with this Socket will block for only this amount of time. If the timeout expires, a java.net.SocketTimeoutException is raised, though the Socket is still valid. The option must be enabled prior to entering the blocking operation to have effect. The timeout must be > 0. A timeout of zero is interpreted as an infinite timeout.
服务端,只要让客户端能连接上就行,不发送数据
1 2 3 4 5
ServerSocket serverSocket = new ServerSocket(8080); while ( true) { Socket socket = serverSocket.accept(); new Thread(new P(socket)).start(); }
客户端,进行读数据
1 2 3
Socket socket = new Socket(); socket.connect(new InetSocketAddress("localhost",8080),20000); socket.setSoTimeout(3000);
3s后,就抛出Read timed out
1 2 3 4 5 6
java.net.SocketTimeoutException: Read timed out at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) at java.net.SocketInputStream.read(SocketInputStream.java:170) at java.net.SocketInputStream.read(SocketInputStream.java:141) at java.net.SocketInputStream.read(SocketInputStream.java:223)
nio
对NIO,看网上一些示例基本没有关注到这一点,所以值得思考,难道是nio不需要关注timeout?
客户端对服务器的连接:
1 2 3 4
Selector selector = Selector.open(); InetSocketAddress isa = new InetSocketAddress(host, port); // 调用open静态方法创建连接到指定主机的SocketChannel SocketChannel sc = SocketChannel.open(isa);
public void connect(){ try{ selector = Selector.open(); InetSocketAddress isa = new InetSocketAddress(host, port); //10秒连接超时 new Timer().schedule(tt, 10000); // 调用open静态方法创建连接到指定主机的SocketChannel sc = SocketChannel.open(isa); // 设置该sc以非阻塞方式工作 sc.configureBlocking(false); // 将Socketchannel对象注册到指定Selector sc.register(selector, SelectionKey.OP_READ); Message msg = new Message(); msg.what = 0; msg.obj = sc; handler.sendMessage(msg); // 连接成功 new Thread(new NIOReceiveThread(selector, handler)).start(); }catch (IOException e) { e.printStackTrace(); handler.sendEmptyMessage(-1); // IO异常 } } TimerTask tt = new TimerTask(){ @Override public void run(){ if (sc == null || !sc.isConnected()){ try{ throw new SocketTimeoutException("连接超时"); }catch (SocketTimeoutException e){ e.printStackTrace(); handler.sendEmptyMessage(-6); // 连接超时 } } } };
在stackoverflow上有人回答了Read timeout for an NIO SocketChannel?
You are using a Selector, in which case you have a select timeout which you can play with, and if it goes off (select(timeout) returns zero) you close all the registered channels, or
You are using blocking mode, in which case you might think you should be able to call Socket.setSoTimeout() on the underlying socket (SocketChannel.socket()), and trap the SocketTimeoutException that is thrown when the timeout expires during read(), but you can’t, because it isn’t supported for sockets originating as channels, or
You are using non-blocking mode without a Selector, in which case you need to change to case (1).
NettyResponseFuture responseFuture = NettyClient.this.removeCallback(response.getRequestId()); if (responseFuture == null) { LoggerUtil.warn( "NettyClient has response from server, but resonseFuture not exist, requestId={}", response.getRequestId()); return null; }
// don't need to notifylisteners, because onSuccess or // onFailure or cancel method already call notifylisteners return getValueOrThrowable(); } else { long waitTime = timeout - (System.currentTimeMillis() - createTime);
if (waitTime > 0) { for (;;) { try { lock.wait(waitTime); } catch (InterruptedException e) { }
// 3.如果连接正在创建中,则加入queue if (target instanceof EmptyChannel) { boolean result = jobs.offer(callback); if (result) { return; } else { throw new RuntimeException("Can't connet to target server and the waiting queue is full"); } }