1、为什么需要自定义类加载器
- 在《类加载器》中讲的,默认类加载器只能加载固定路径下的class,如果有特定路径下的class,需要自定义
- 安全性:系统自身需要一些jar,class,如果业务类代码中也有相同的class,破坏系统,类似双亲委托安全性
可以看看tomcat自定义类加载器的原因,别的就大同小异了
1 | a)、要保证部署在tomcat上的每个应用依赖的类库相互独立,不受影响。 |
2、自定义加载器
这儿主要说下我司的自定义类加载器;更复杂点的可以看看tomcat的类加载机制
为什么需要自定义类加载器?这可以参考章节1的答案
主要在于应用与基础平台的隔离,相对应用:可以有更大技术选型自由度,不用考虑基础平台的jar包版本、相对平台:更可靠安全,不被应用class影响
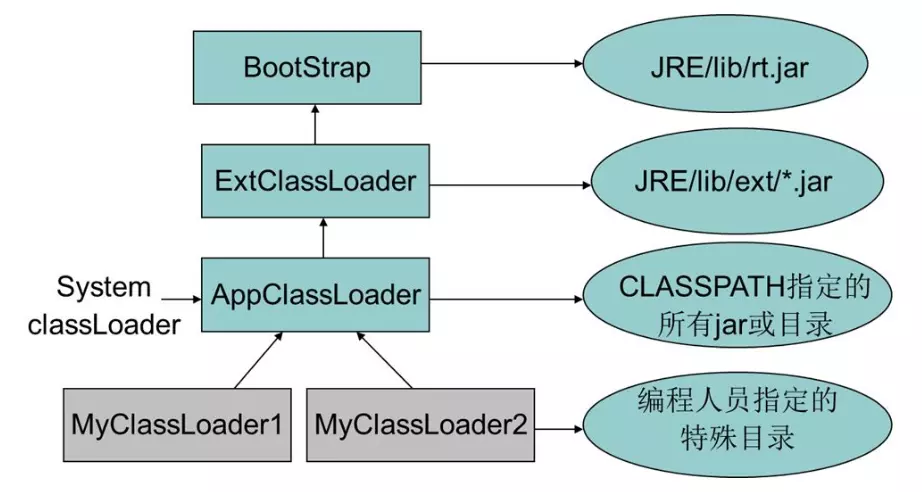
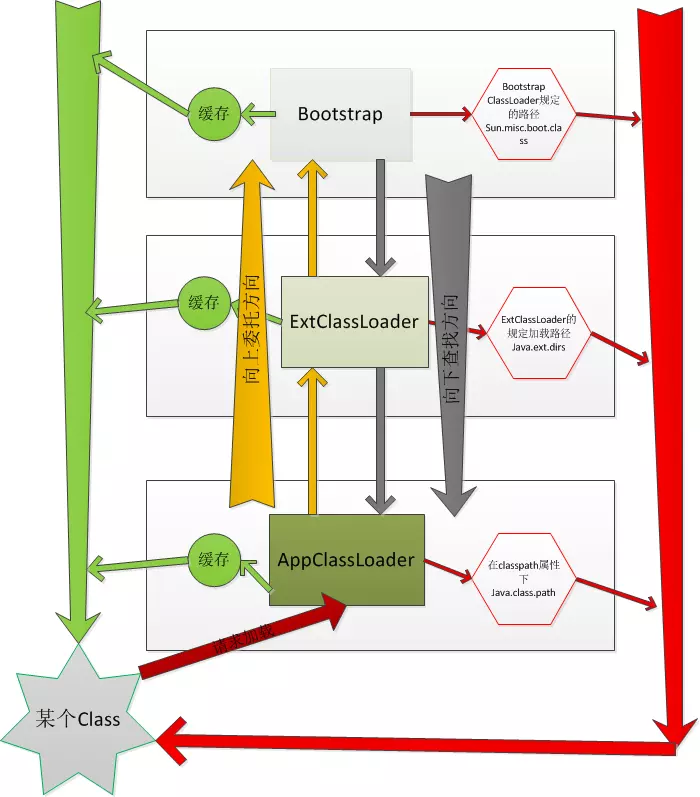
类加载器结构
虽然JAVA使用了类加载的委派机制,但并没严格要求开发者必须遵守该机制,我们可以打破这种”双亲委派”机制
目录结构
| 目录 | 说明 |
|---|---|
| /servicesdir | 业务实现jar包 |
| /thirddir | 业务依赖jar包 |
| /platformdir | 平台依赖jar包 |
类加载器
- 1.PlatformClassLoader平台加载器
- 1.1.加载/platformdir下的jar包
- 1.2.在加载时,采用了默认的“双亲委派”
- 2.AppClassLoader应用加载器
- 2.1.加载/servicesdir,/thirddir下的jar
- 2.2.该类加载器一定程度上打破了默认的“双亲委派”
- 2.2.0.loadClass方法中,如果本加载器没有load到对应的类,则会检查该类是否处于平台类加载器白名单中:
- 2.2.1.如果处于白名单中,则委派PlatformClassLoader加载
- 2.2.2.否则,通过super.loadClass(String,boolean)走默认的双亲委派
此处白名单类:平台核心类,不能被同名业务类干扰
预加载
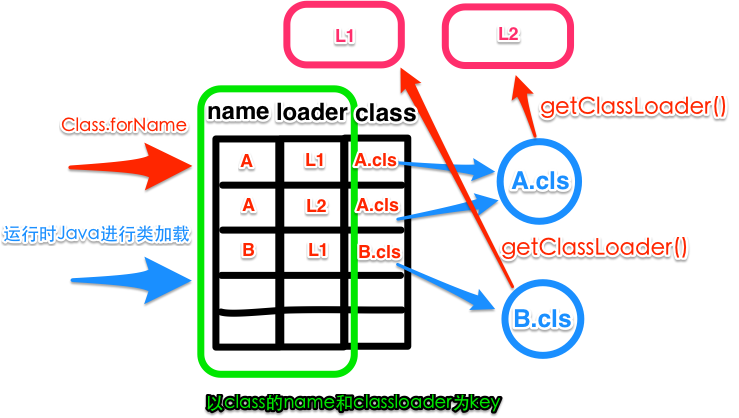
《类加载器》中说过,程序启动后,并不会加载所有类,在运行中实现到时,才会去加载。这儿就有性能损耗。
按类加载规则,一个类只加载一次
可以测试一下,加载需要的损耗
1 | /** |
可以从输出看到性能损耗是不小的,这部分损耗可以通过预加载来消除
随着程序运行时间越久,被触发的业务越多,那加载到的业务类越多。
预加载类的逻辑
ClassWarmUp
- 1.在classloader中loadClass时,把className加入到LinkedBlockingDeque中
- 2.为了性能,异步把deque中的class写入到文件中,需要起一个后台线程
- 2.1 后台线程,从deque中取出class,写入到文件中
- 3.下次从文件中预先加载class
打包
对于/servicesdir 与 /thirddir 都好处理,但对于platformdir是怎么打包的呢?毕竟在开发时,只是引入一个平台基础jar就行
使用
有了自定义类加载器,在应用主函数中,就不能直接new了,不然就会使用AppClassLoader
所以需要使用反射机制
1 | Class<?> loadClass = platformClassLoader.loadClass("com.jack.Start"); |
这样,通过Start加载的类也会通过platformClassLoader去加载
创建springcontext也一样,这儿还需使用到Thread.currentThread().getContextClassLoader()【下面有详解】
1 | ClassLoader currentThreadLoader = Thread.currentThread().getContextClassLoader(); |
3、反常
“双亲委派”模型有优点,也有力不从心的地方
Java 提供了很多服务提供者接口(Service Provider Interface,SPI),允许第三方为这些接口提供实现。常见的 SPI 有 JDBC、JCE、JNDI、JAXP 和 JBI 等。
这些 SPI 的接口由 Java 核心库来提供,而这些 SPI 的实现代码则是作为 Java 应用所依赖的 jar 包被包含进类路径(CLASSPATH)里。SPI接口中的代码经常需要加载具体的实现类。那么问题来了,SPI的接口是Java核心库的一部分,是由启动类加载器(Bootstrap Classloader)来加载的;SPI的实现类是由系统类加载器(System ClassLoader)来加载的。引导类加载器是无法找到 SPI 的实现类的,因为依照双亲委派模型,BootstrapClassloader无法委派AppClassLoader来加载类。
而线程上下文类加载器破坏了“双亲委派模型”,可以在执行线程中抛弃双亲委派加载链模式,使程序可以逆向使用类加载器。
场景:
- 当高层提供了统一的接口让低层去实现,同时又要在高层加载(或者实例化)低层的类时,就必须要通过线程上下文类加载器来帮助高层的ClassLoader找到并加载该类
- 当使用本类托管类加载,然而加载本类的ClassLoader未知时,为了隔离不同的调用者,可以取调用者各自的线程上下文类加载器代为托管
解决方案:
从jdk1.2开始引入的,类Thread中的getContextClassLoader()与setContextClassLoader(ClassLoader c1),分别用来获取和设置类加载器
一般使用模式:获取-使用-还原
1 | ClassLoader classLoader = Thread.currentThread().getContextClassLoader(); |
jdbc
以jdbc看下场景1的情况
1 | Class.forName("com.mysql.jdbc.Driver") |
- 1.Class.forName(“com.mysql.jdbc.Driver”); 在com.mysql.jdbc.Driver中
1 | public class Driver extends NonRegisteringDriver implements java.sql.Driver { |
通过Class.forName(),主要就是执行初始化static代码块,也就是向DriverManager注册Driver
此时:应用类、Driver是由AppClassLoader加载,但由于双亲委派java.sql.DriverManager是由BootstrapClassLoader加载
- 2.java.sql.DriverManager.getConnection 获取连接
1 | private static Connection getConnection( |
这其中有两行代码:
1 | callerCL = Thread.currentThread().getContextClassLoader(); |
这儿是取线程上下文中的classloader,也就是AppClassLoader;如果不取此classloader,那么Class.forName(driverClassName)就是使用DriverManager的BootstrapClassLoader加载,那必然是加载不到,这也就是父层类加载器加载不了低层类。
还有个问题,为什么在应用程序中已经加载过Driver,到了getConnection()又要再加载,还得通过Thread.currentThread().getContextClassLoader()?
其实在getConnection()中,只是对比class是否是同一个,像tomcat那样,各个应用都有自己的mysql-driver的jar包,就只能通过classloader来区分,因为class是不是相同需要classname+classloader组合鉴别
spring
对于场景2的问题
如果有 10 个 Web 应用程序都用到了spring的话,可以把Spring的jar包放到 common 或 shared 目录下让这些程序共享。Spring 的作用是管理每个web应用程序的bean,getBean时自然要能访问到应用程序的类,而用户的程序显然是放在 /WebApp/WEB-INF 目录中的(由 WebAppClassLoader 加载),那么在 CommonClassLoader 或 SharedClassLoader 中的 Spring 容器如何去加载并不在其加载范围的用户程序(/WebApp/WEB-INF/)中的Class呢?
答案呼之欲出:spring根本不会去管自己被放在哪里,它统统使用线程上下文加载器来加载类,而线程上下文加载器默认设置为了WebAppClassLoader,也就是说哪个WebApp应用调用了spring,spring就去取该应用自己的WebAppClassLoader来加载bean
org.springframework.web.context.ContextLoader类
1 | public WebApplicationContext initWebApplicationContext(ServletContext servletContext) { |
关键代码:
1 | // 获取线程上下文类加载器,默认为WebAppClassLoader |
这样做的目的在于当通过ConetxtLoader的静态方法获取context的时候,能保证获取的是当前web application的context.实际上就是对于tomcat下面的任何一个线程,我们都能很方便的找出这个线程对应的webapplicationContext.于是在一些不能方便获取servletContext的场合,我们可以通过当前线程获取webapplicationContext.
1 | public static WebApplicationContext getCurrentWebApplicationContext() { |
总结
简而言之就是ContextClassLoader默认存放了AppClassLoader的引用,由于它是在运行时被放在了线程中,所以不管当前程序处于何处(BootstrapClassLoader或是ExtClassLoader等),在任何需要的时候都可以用Thread.currentThread().getContextClassLoader()取出应用程序类加载器来完成需要的操作