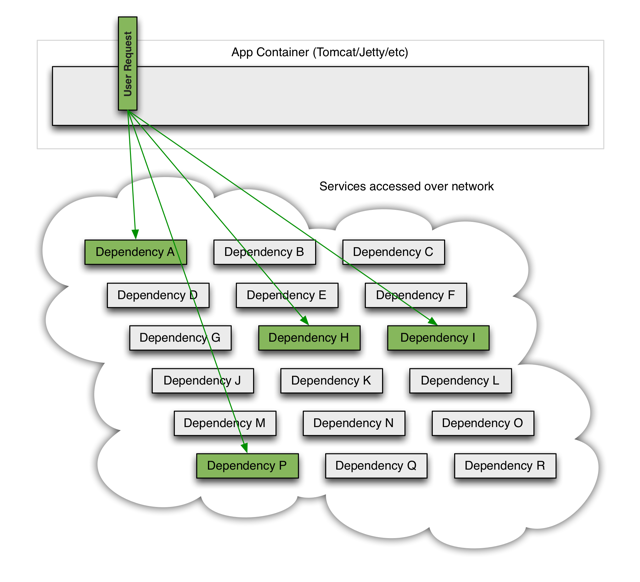
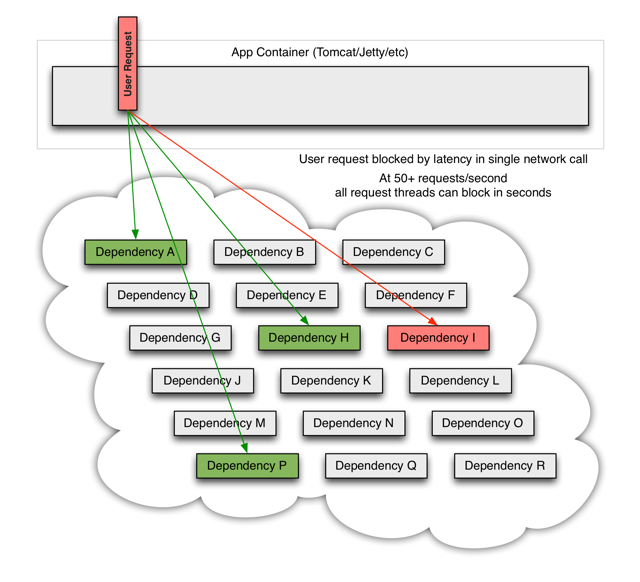
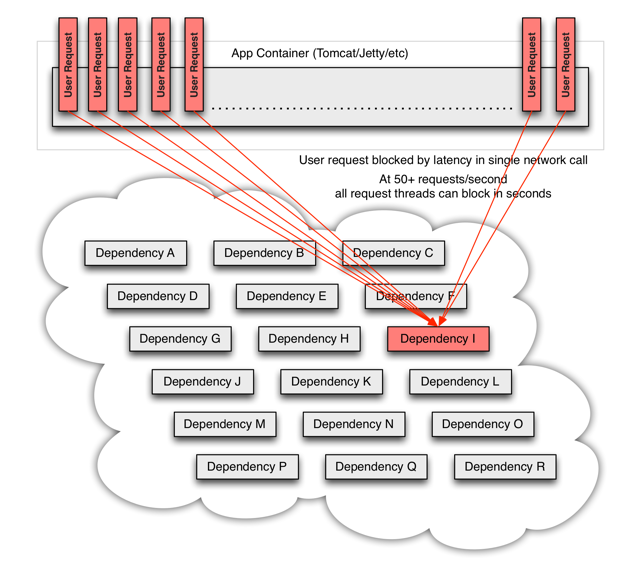
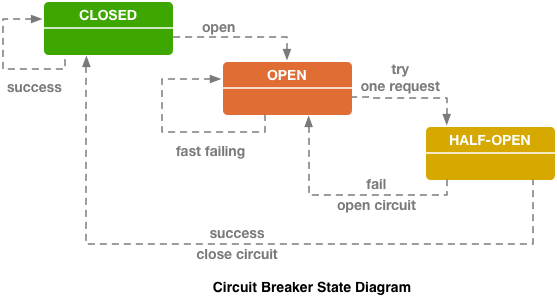
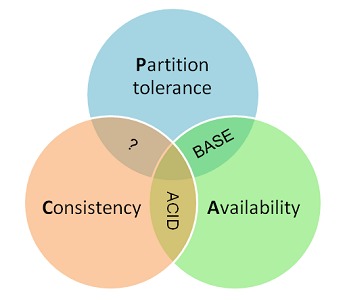
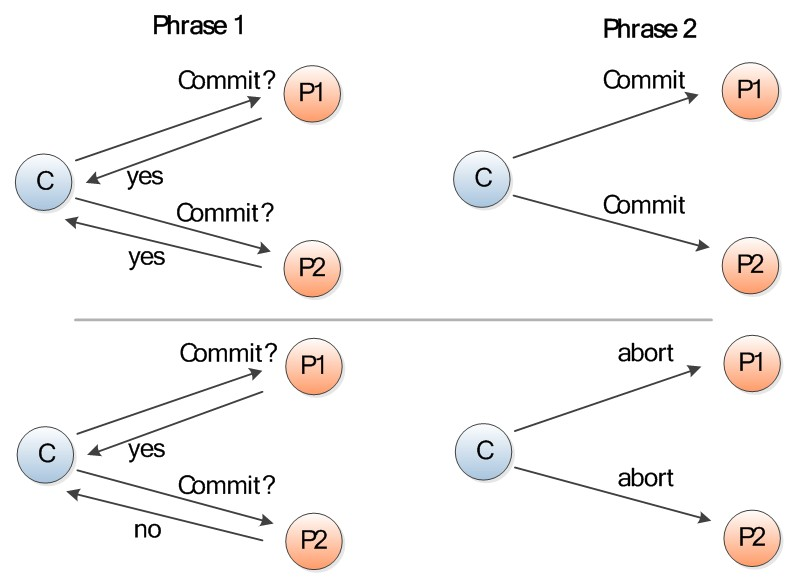
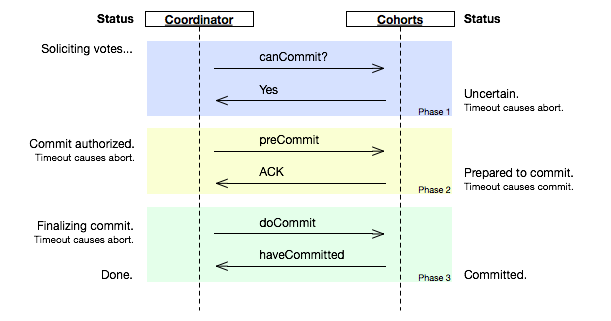
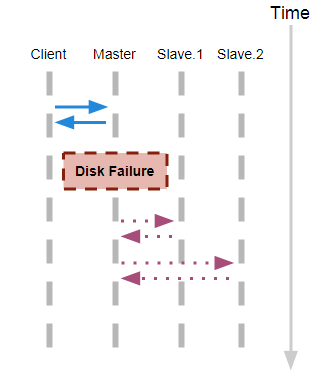
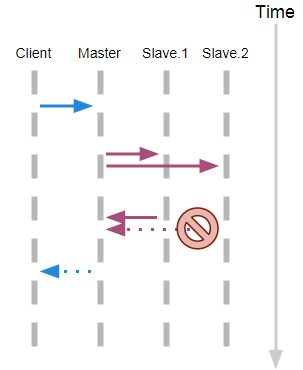
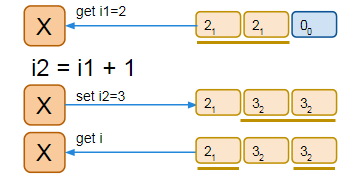
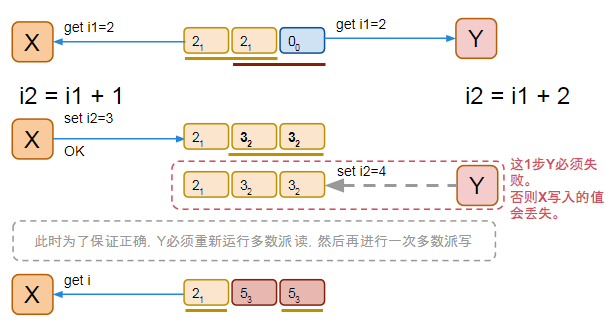
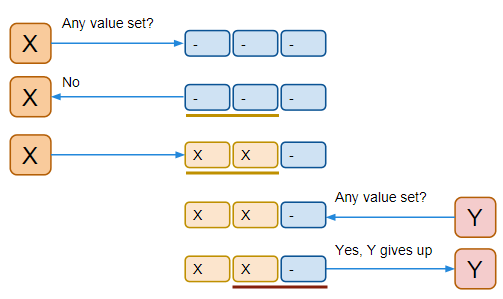
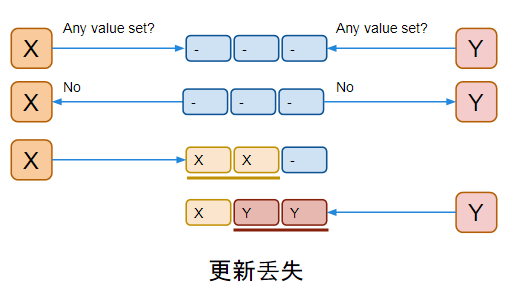
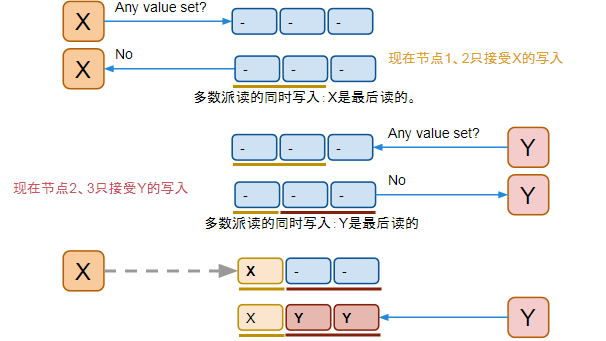
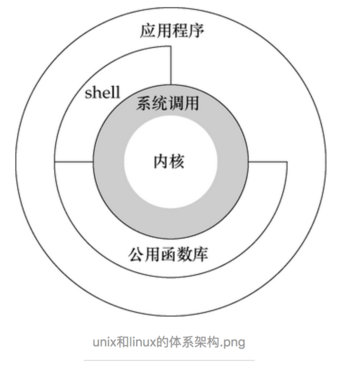
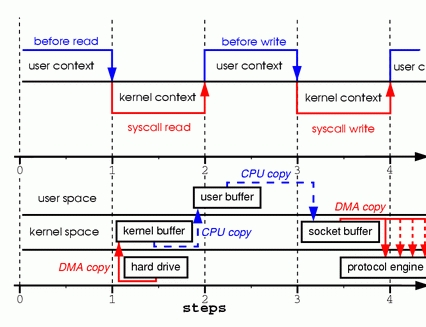
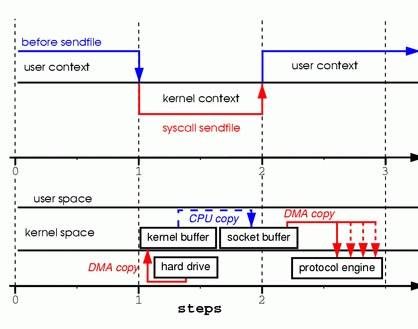
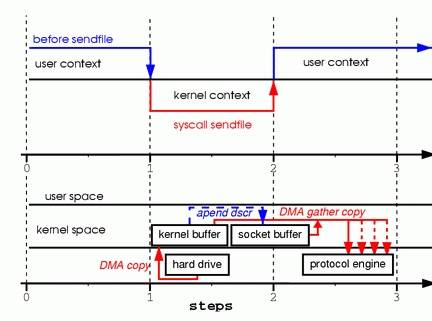
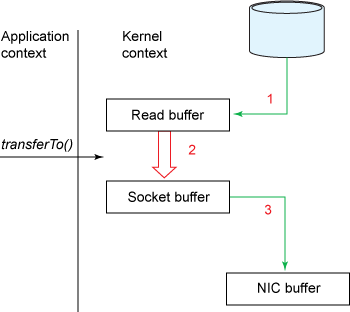
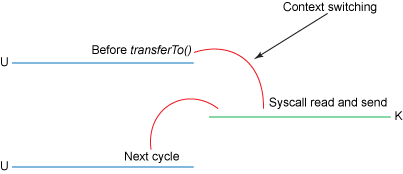
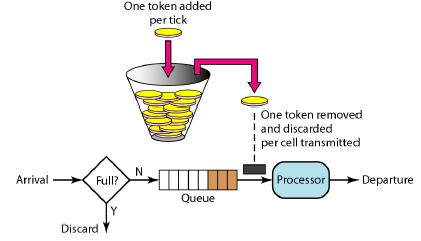
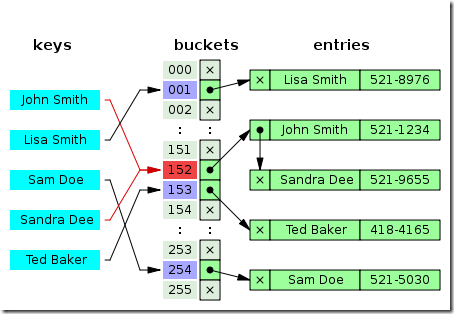
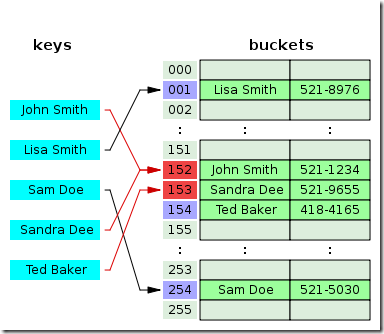
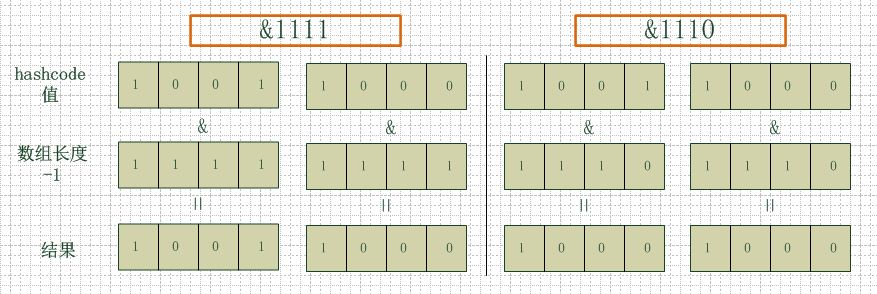
A memory model describes, given a program and an execution trace of that program, whether the execution trace is a legal execution of the program. For the Java programming language, the memory model works by examining each read in an execution trace and checking that the write observed by that read is valid according to certain rules.
Writes and reads of volatile long and double values are always atomic. Writes to and reads of references are always atomic, regardless of whether they are implemented as 32-bit or 64-bit values.
class VolatileExample { int a = 0; volatile boolean flag = false; public void writer() { a = 1; //1 flag = true; //2 } public void reader() { if (flag) { //3 int i = a; //4 …… } } }
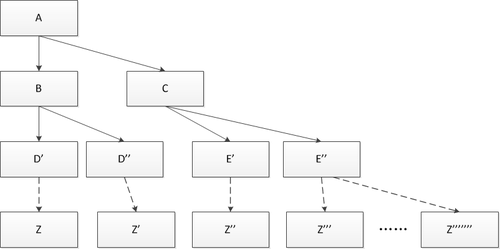
假设线程A执行writer()方法之后,线程B执行reader()方法。根据happens before规则,这个过程建立的happens before 关系可以分为两类: · 根据程序次序规则,1 happens before 2; 3 happens before 4。 · 根据volatile规则,2 happens before 3。 · 根据happens before 的传递性规则,1 happens before 4。 上述happens before 关系的图形化表现形式如下:
在上图中,每一个箭头链接的两个节点,代表了一个happens before 关系。黑色箭头表示程序顺序规则;橙色箭头表示volatile规则;蓝色箭头表示组合这些规则后提供的happens before保证。
Each object is associated with a monitor. A monitor is locked if and only if it has an owner. The thread that executes monitorenter attempts to gain ownership of the monitor associated with objectref, as follows: • If the entry count of the monitor associated with objectref is zero, the thread enters the monitor and sets its entry count to one. The thread is then the owner of the monitor. • If the thread already owns the monitor associated with objectref, it reenters the monitor, incrementing its entry count. • If another thread already owns the monitor associated with objectref, the thread blocks until the monitor’s entry count is zero, then tries again to gain ownership.
The thread that executes monitorexit must be the owner of the monitor associated with the instance referenced by objectref. The thread decrements the entry count of the monitor associated with objectref. If as a result the value of the entry count is zero, the thread exits the monitor and is no longer its owner. Other threads that are blocking to enter the monitor are allowed to attempt to do so.
class SynchronizedExample { int a = 0; boolean flag = false; public synchronized void writer() { a = 1; flag = true; } public synchronized void reader() { if (flag) { int i = a; …… } } }
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不做任何操作。无论哪种情况,它都会在 CAS 指令之前返回该位置的值。 (在 CAS 的一些特殊情况下将仅返回 CAS 是否成功,而不提取当前值。) CAS 有效地说明了“我认为位置 V 应该包含值 A;如果包含该值,则将 B 放到这个位置; 否则,不要更改该位置,只告诉我这个位置现在的值即可。”这其实和乐观锁的冲突检查+数据更新的原理是一样的。
1 2 3
public final boolean compareAndSet(int expect, int update) { return unsafe.compareAndSwapInt(this, valueOffset, expect, update); }
// Adding a lock prefix to an instruction on MP machine // VC++ doesn't like the lock prefix to be on a single line // so we can't insert a label after the lock prefix. // By emitting a lock prefix, we can define a label after it. #define LOCK_IF_MP(mp) __asm cmp mp, 0 \ __asm je L0 \ __asm _emit 0xF0 \ __asm L0:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) { // alternative for InterlockedCompareExchange int mp = os::is_MP(); __asm { mov edx, dest mov ecx, exchange_value mov eax, compare_value LOCK_IF_MP(mp) cmpxchg dword ptr [edx], ecx } }
循环时间长开销大。自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
coordinator接收完participant的反馈(vote)之后,进入阶段2,给各个participant发送准备提交(prepare to commit)指令。participant接到准备提交指令后可以锁资源,但要求相关操作必须可回滚。coordinator接收完确认(ACK)后进入阶段3、进行commit/abort,3PC的阶段3与2PC的阶段2无异。协调者备份(coordinator watchdog)、状态记录(logging)同样应用在3PC。
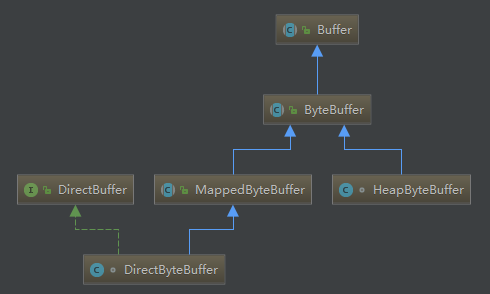
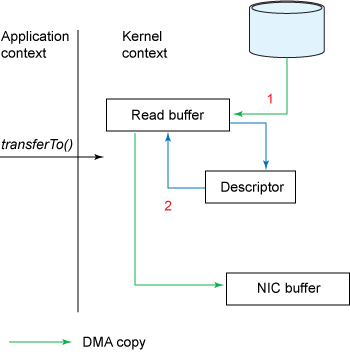
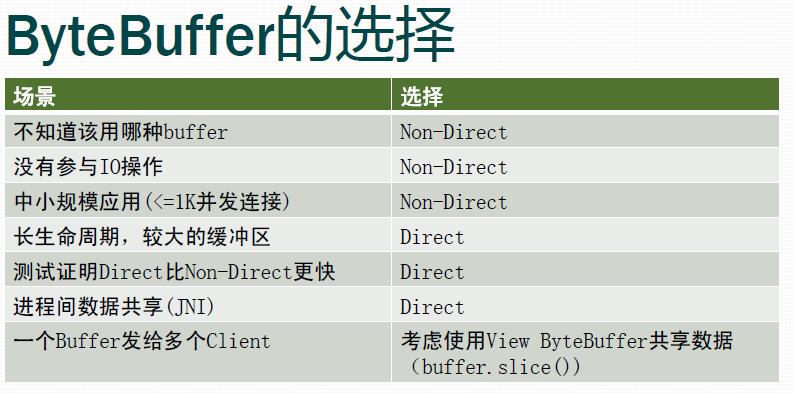
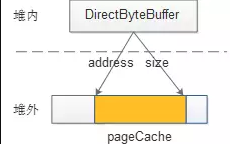
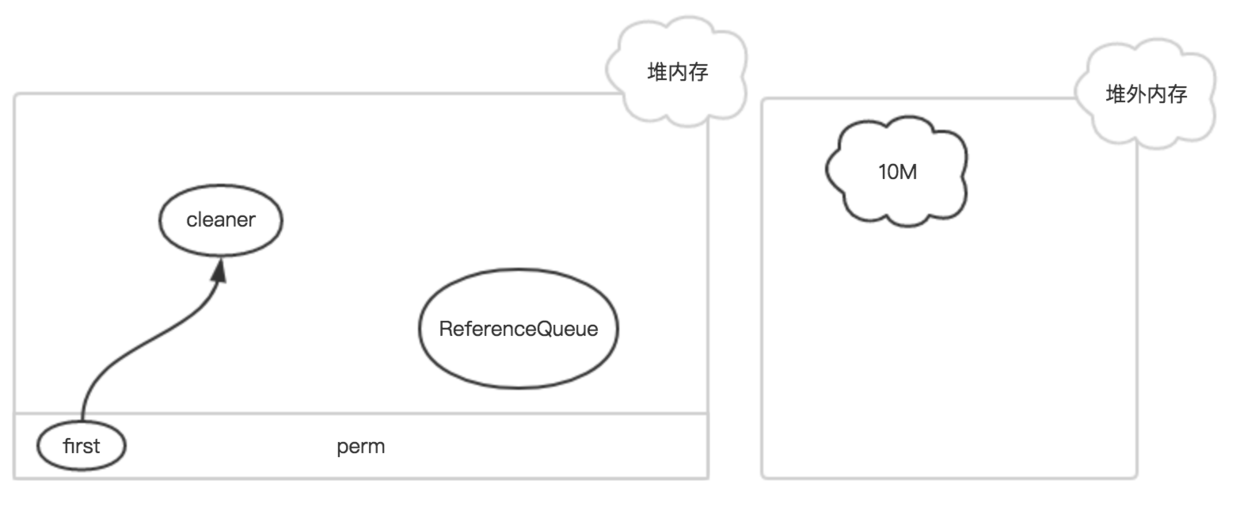
A byte buffer is either direct or non-direct. Given a direct byte buffer, the Java virtual machine will make a best effort to perform native I/O operations directly upon it. That is, it will attempt to avoid copying the buffer’s content to (or from) an intermediate buffer before (or after) each invocation of one of the underlying operating system’s native I/O operations. A direct byte buffer may be created by invoking the allocateDirect factory method of this class. The buffers returned by this method typically have somewhat higher allocation and deallocation costs than non-direct buffers. The contents of direct buffers may reside outside of the normal garbage-collected heap, and so their impact upon the memory footprint of an application might not be obvious. It is therefore recommended that direct buffers be allocated primarily for large, long-lived buffers that are subject to the underlying system’s native I/O operations. In general it is best to allocate direct buffers only when they yield a measureable gain in program performance. A direct byte buffer may also be created by mapping a region of a file directly into memory. An implementation of the Java platform may optionally support the creation of direct byte buffers from native code via JNI. If an instance of one of these kinds of buffers refers to an inaccessible region of memory then an attempt to access that region will not change the buffer’s content and will cause an unspecified exception to be thrown either at the time of the access or at some later time.
class HeapByteBuffer extends ByteBuffer { HeapByteBuffer(int cap, int lim) { // package-private
super(-1, 0, lim, cap, new byte[cap], 0); /* hb = new byte[cap]; offset = 0; */ } } public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer> {
// These fields are declared here rather than in Heap-X-Buffer in order to // reduce the number of virtual method invocations needed to access these // values, which is especially costly when coding small buffers. // final byte[] hb; // Non-null only for heap buffers final int offset; boolean isReadOnly; // Valid only for heap buffers
// Creates a new buffer with the given mark, position, limit, capacity, // backing array, and array offset // ByteBuffer(int mark, int pos, int lim, int cap, // package-private byte[] hb, int offset) { super(mark, pos, lim, cap); this.hb = hb; this.offset = offset; }
static void reserveMemory(long size, int cap) { synchronized (Bits.class) { if (!memoryLimitSet && VM.isBooted()) { maxMemory = VM.maxDirectMemory(); memoryLimitSet = true; } // -XX:MaxDirectMemorySize limits the total capacity rather than the // actual memory usage, which will differ when buffers are page // aligned. if (cap <= maxMemory - totalCapacity) { reservedMemory += size; totalCapacity += cap; count++; return; } }
System.gc(); try { Thread.sleep(100); } catch (InterruptedException x) { // Restore interrupt status Thread.currentThread().interrupt(); } synchronized (Bits.class) { if (totalCapacity + cap > maxMemory) throw new OutOfMemoryError("Direct buffer memory"); reservedMemory += size; totalCapacity += cap; count++; } }
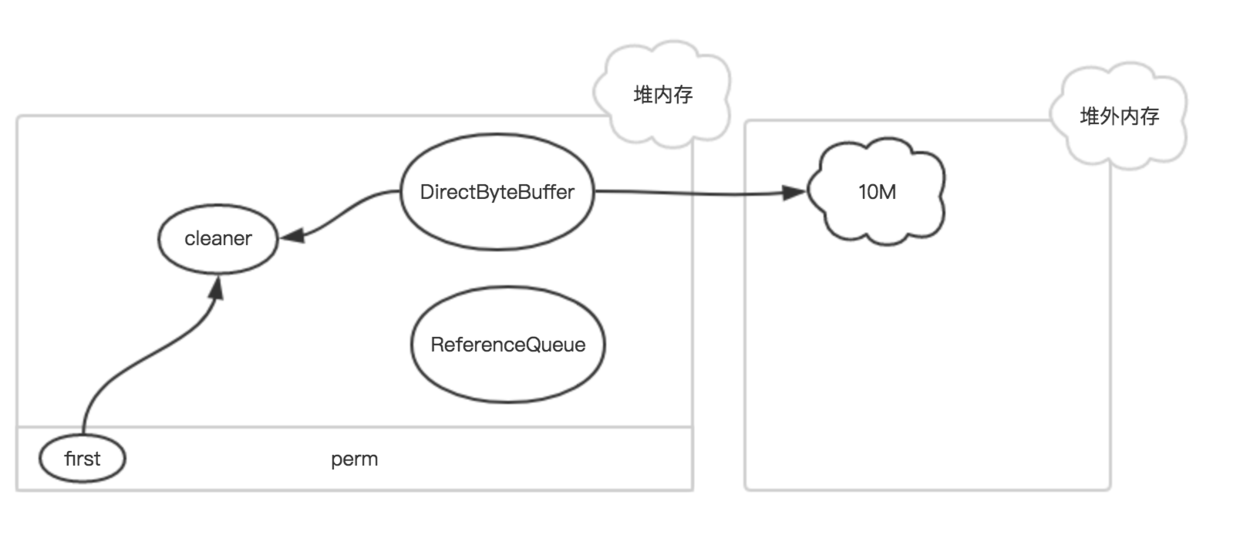
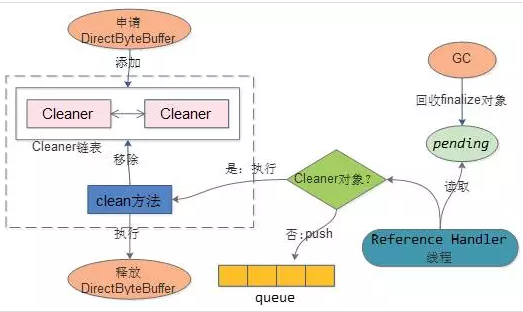
public class Cleaner extends PhantomReference<Object> { private static final ReferenceQueue<Object> dummyQueue = new ReferenceQueue(); private static Cleaner first = null; private Cleaner next = null; private Cleaner prev = null; private final Runnable thunk;
public void run() { for (;;) { Reference<Object> r; synchronized (lock) { if (pending != null) { r = pending; pending = r.discovered; r.discovered = null; } else { // The waiting on the lock may cause an OOME because it may try to allocate // exception objects, so also catch OOME here to avoid silent exit of the // reference handler thread. // // Explicitly define the order of the two exceptions we catch here // when waiting for the lock. // // We do not want to try to potentially load the InterruptedException class // (which would be done if this was its first use, and InterruptedException // were checked first) in this situation. // // This may lead to the VM not ever trying to load the InterruptedException // class again. try { try { lock.wait(); } catch (OutOfMemoryError x) { } } catch (InterruptedException x) { } continue; } }
// Fast path for cleaners if (r instanceof Cleaner) { ((Cleaner)r).clean(); continue; }
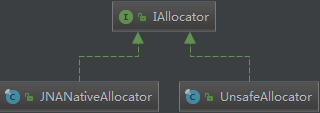
JNA provides Java programs easy access to native shared libraries without writing anything but Java code - no JNI or native code is required
堆外缓存OHC便是使用JNA来申请堆外空间。
线下测试:JNA内存申请的性能是unsafe(JNI)的2倍。
Why not use ByteBuffer.allocateDirect()?
TL;DR allocating off-heap memory directly and bypassing ByteBuffer.allocateDirect is very gentle to the GC and we have explicit control over memory allocation and, more importantly, free. The stock implementation in Java frees off-heap memory during a garbage collection - also: if no more off-heap memory is available, it likely triggers a Full-GC, which is problematic if multiple threads run into that situation concurrently since it means lots of Full-GCs sequentially. Further, the stock implementation uses a global, synchronized linked list to track off-heap memory allocations.
This is why OHC allocates off-heap memory directly and recommends to preload jemalloc on Linux systems to improve memory managment performance.
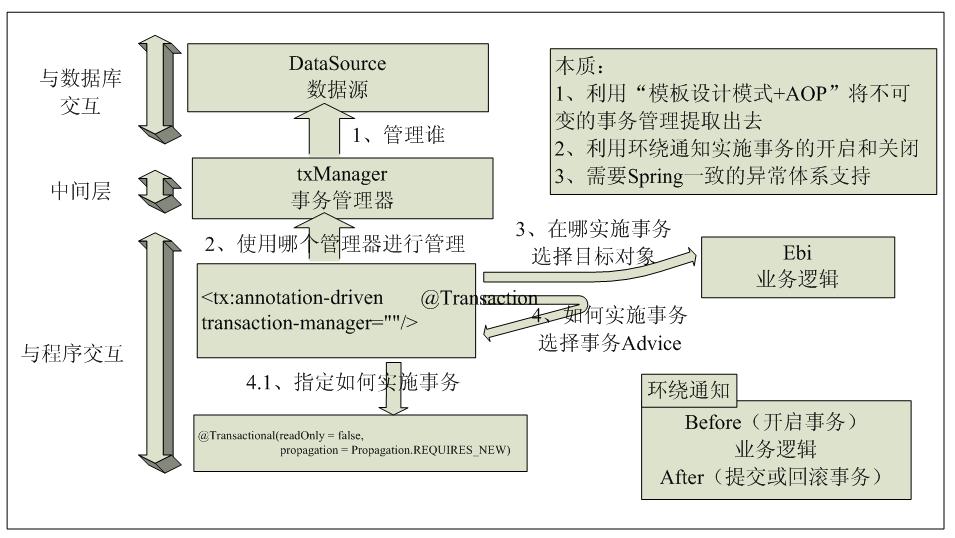
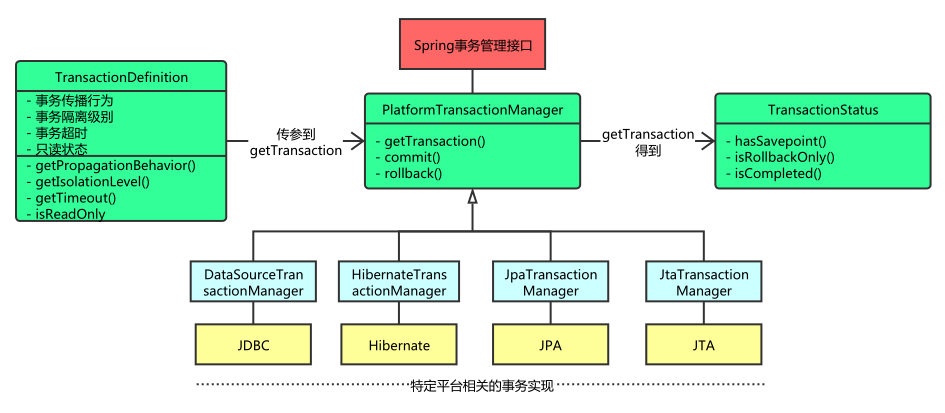
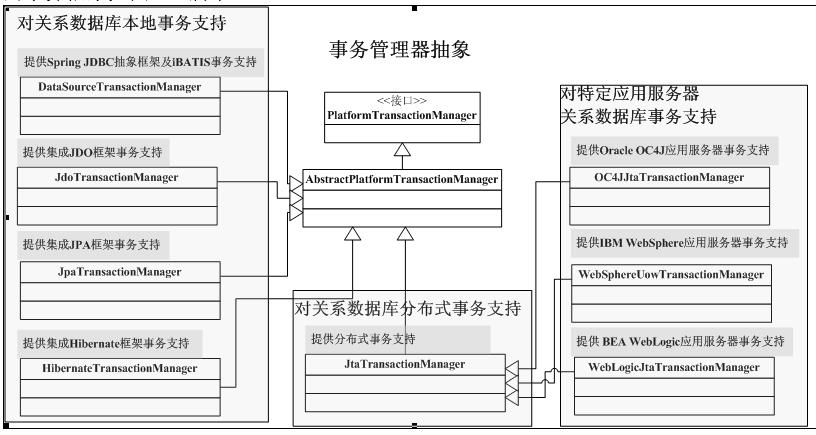
/** * This is the central interface in Spring's transaction infrastructure. * Applications can use this directly, but it is not primarily meant as API: * Typically, applications will work with either TransactionTemplate or * declarative transaction demarcation through AOP. */ public interface PlatformTransactionManager { TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException; void commit(TransactionStatus status) throws TransactionException; void rollback(TransactionStatus status) throws TransactionException; }
@Override public void init() { registerBeanDefinitionParser("advice", new TxAdviceBeanDefinitionParser()); registerBeanDefinitionParser("annotation-driven", new AnnotationDrivenBeanDefinitionParser()); registerBeanDefinitionParser("jta-transaction-manager", new JtaTransactionManagerBeanDefinitionParser()); }
主要是TransactionInterceptor类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
public Object invoke(final MethodInvocation invocation) throws Throwable { // Work out the target class: may be {@code null}. // The TransactionAttributeSource should be passed the target class // as well as the method, which may be from an interface. Class<?> targetClass = (invocation.getThis() != null ? AopUtils.getTargetClass(invocation.getThis()) : null);
// Adapt to TransactionAspectSupport's invokeWithinTransaction... //主要逻辑在父类 return invokeWithinTransaction(invocation.getMethod(), targetClass, new InvocationCallback() { @Override public Object proceedWithInvocation() throws Throwable { return invocation.proceed(); } }); }
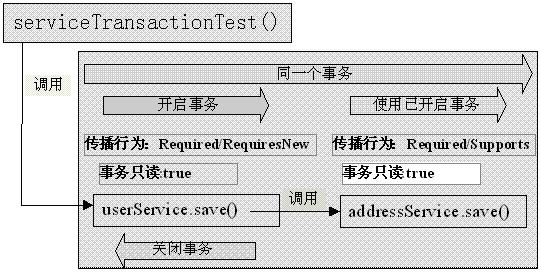
if (txAttr == null || !(tm instanceof CallbackPreferringPlatformTransactionManager)) { // Standard transaction demarcation with getTransaction and commit/rollback calls. // 判断创建Transaction TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification); Object retVal = null; try { // This is an around advice: Invoke the next interceptor in the chain. // This will normally result in a target object being invoked. //执行业务逻辑 retVal = invocation.proceedWithInvocation(); } catch (Throwable ex) { // target invocation exception // 出现异常,回滚 completeTransactionAfterThrowing(txInfo, ex); throw ex; } finally { //清除当前事务状态 cleanupTransactionInfo(txInfo); } //提交事务 commitTransactionAfterReturning(txInfo); return retVal; }
public final TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException { //得到各个不同数据源的事务对象,spring尽然没有把transaction对象抽象出来,很是奇怪 Object transaction = doGetTransaction();
// Cache debug flag to avoid repeated checks. boolean debugEnabled = logger.isDebugEnabled();
if (definition == null) { // Use defaults if no transaction definition given. definition = new DefaultTransactionDefinition(); }
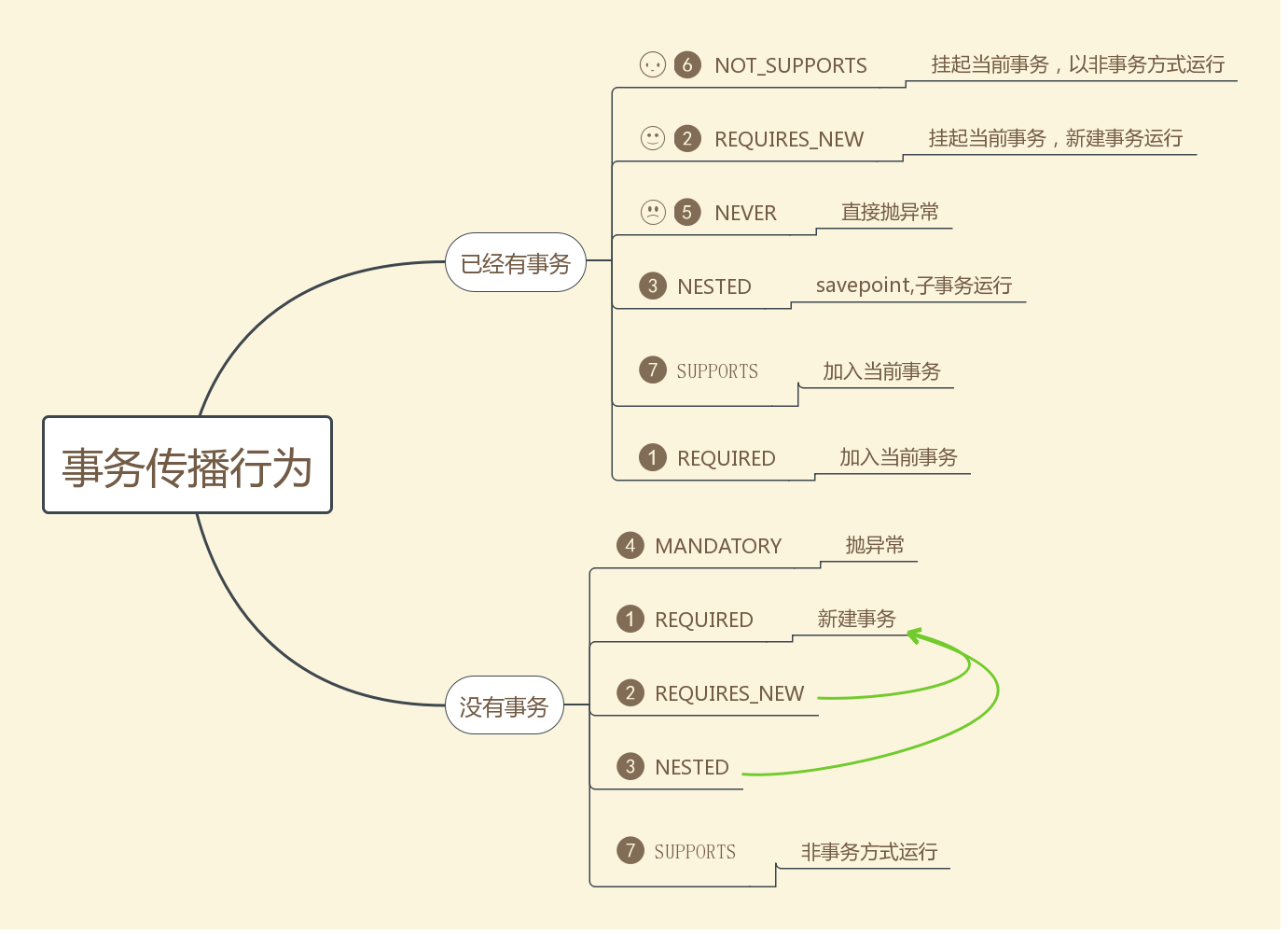
//此事务是否已经存在 if (isExistingTransaction(transaction)) { // Existing transaction found -> check propagation behavior to find out how to behave. return handleExistingTransaction(definition, transaction, debugEnabled); }
// Check definition settings for new transaction. if (definition.getTimeout() < TransactionDefinition.TIMEOUT_DEFAULT) { throw new InvalidTimeoutException("Invalid transaction timeout", definition.getTimeout()); }
// No existing transaction found -> check propagation behavior to find out how to proceed. if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_MANDATORY) { throw new IllegalTransactionStateException( "No existing transaction found for transaction marked with propagation 'mandatory'"); } //这三种都是新建事务 else if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRED || definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW || definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) { SuspendedResourcesHolder suspendedResources = suspend(null); if (debugEnabled) { logger.debug("Creating new transaction with name [" + definition.getName() + "]: " + definition); } try { boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER); DefaultTransactionStatus status = newTransactionStatus( definition, transaction, true, newSynchronization, debugEnabled, suspendedResources); //开始获取链接,开启事务,绑定资源到当前线程 doBegin(transaction, definition); prepareSynchronization(status, definition); return status; } catch (RuntimeException | Error ex) { resume(null, suspendedResources); throw ex; } } else { // Create "empty" transaction: no actual transaction, but potentially synchronization. if (definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT && logger.isWarnEnabled()) { logger.warn("Custom isolation level specified but no actual transaction initiated; " + "isolation level will effectively be ignored: " + definition); } boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS); return prepareTransactionStatus(definition, null, true, newSynchronization, debugEnabled, null); } }
TransactionStatus
这儿返回的是TransactionStatus
1 2 3 4 5 6 7 8 9 10 11 12 13
public interface TransactionStatus extends SavepointManager, Flushable {
boolean isNewTransaction();
boolean hasSavepoint();
void setRollbackOnly();
boolean isRollbackOnly();
void flush();
boolean isCompleted();
TransactionInfo
事务信息
1 2 3 4 5 6 7 8 9 10 11 12 13
protected final class TransactionInfo {
private final PlatformTransactionManager transactionManager;
private final TransactionAttribute transactionAttribute;
// Raise UnexpectedRollbackException if we had a global rollback-only marker if (unexpectedRollback) { throw new UnexpectedRollbackException( "Transaction rolled back because it has been marked as rollback-only"); } } finally { cleanupAfterCompletion(status); }
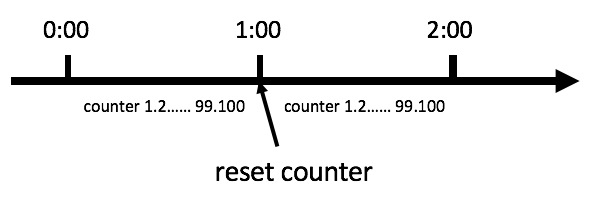
public class Counter { public long timeStamp = getNowTime(); public int reqCount = 0; public final int limit = 100; // 时间窗口内最大请求数 public final long interval = 1000; // 时间窗口ms public boolean grant() { long now = getNowTime(); if (now < timeStamp + interval) { // 在时间窗口内 reqCount++; // 判断当前时间窗口内是否超过最大请求控制数 return reqCount <= limit; } else { timeStamp = now; // 超时后重置 reqCount = 1; return true; } } }
//一个并发安全map,skip list有序 this.measurements = new ConcurrentSkipListMap<Long, Long>();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
/** * 获取map的key,以时间纳秒值为key * @return */ private long getTick() { for (; ; ) { final long oldTick = lastTick.get(); //每纳秒处理的请求很多,减少compareAndSet的失败次数,这儿*COLLISION_BUFFER final long tick = clock.getTick() * COLLISION_BUFFER; // ensure the tick is strictly incrementing even if there are duplicate ticks final long newTick = tick > oldTick ? tick : oldTick + 1; if (lastTick.compareAndSet(oldTick, newTick)) { return newTick; } } }
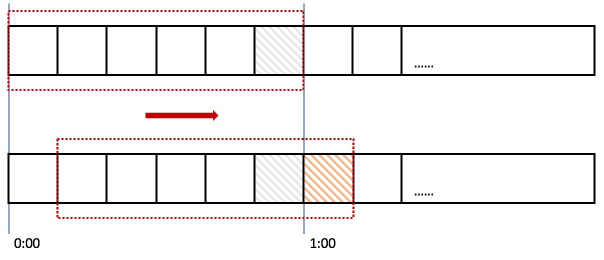
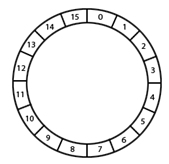
private int window; //计算窗口 //整个循环数组窗口 private int ringWindow=window+30;
requestCounter = new AtomicInteger[ringWindow]; failedCounter = new AtomicInteger[ringWindow]; for (int i = 0; i < ringWindow; i++) { requestCounter[i] = new AtomicInteger(0); failedCounter[i] = new AtomicInteger(0); }
private long countTotal(AtomicInteger[] caculateCounter){ int currentIndex = getIndex(); long sum = 0; for (int i = 0; i < window; i++) { //这儿并不是直接计算window中的所有counter, //而是从currentIndex向前倒取window个 int index = ((currentIndex + ringWindow) -i) % this.ringWindow; sum += caculateCounter[index].get(); } return sum; }
为什么需要ringWindow,直接window就可以?这儿有个奇技淫巧。
1 2 3 4 5 6 7 8 9 10 11
CLEAN_UP_BUFFER=10;
public void cleanupFutureCounter() { int currentIndex = getIndex(); for (int i = 1 ; i <= CLEAN_UP_BUFFER; i++) { int index = (currentIndex + i) % this.ringWindow; requestCounter[index].set(0); failedCounter[index].set(0); } }
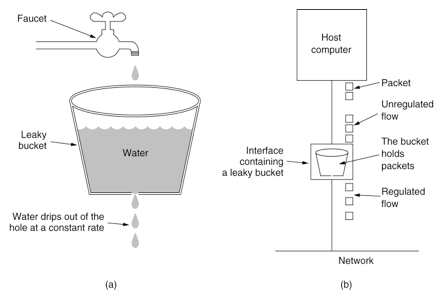
public class LeakyDemo { public long timeStamp = getNowTime(); public int capacity; // 桶的容量 public int rate; // 水漏出的速度 public int water; // 当前水量(当前累积请求数) public boolean grant() { long now = getNowTime(); water = max(0, water - (now - timeStamp) * rate); // 先执行漏水,计算剩余水量 timeStamp = now; if ((water + 1) < capacity) { // 尝试加水,并且水还未满 water += 1; return true; } else { // 水满,拒绝加水 return false; } } }
public class TokenBucketDemo { public long timeStamp = getNowTime(); public int capacity; // 桶的容量 public int rate; // 令牌放入速度 public int tokens; // 当前令牌数量 public boolean grant() { long now = getNowTime(); // 先添加令牌 tokens = min(capacity, tokens + (now - timeStamp) * rate); timeStamp = now; if (tokens < 1) { // 若不到1个令牌,则拒绝 return false; } else { // 还有令牌,领取令牌 tokens -= 1; return true; } } }
/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/** * The maximum capacity, used if a higher value is implicitly specified * by either of the constructors with arguments. * MUST be a power of two <= 1<<30. */ static final int MAXIMUM_CAPACITY = 1 << 30;
/** * The load factor used when none specified in constructor. */ static final float DEFAULT_LOAD_FACTOR = 0.75f;
为了弄清楚这个问题,Bruce Eckel(Thinking in JAVA的作者)专程采访了java.util.hashMap的作者Joshua Bloch,此设计的原因 取模运算在包括Java在内的大多数语言中的效率都十分低下,而当除数为2的N次方时,取模运算将退化为最简单的位运算,其效率明显提升(按照Bruce Eckel给出的数据,大约可以提升5~8倍)
1 2 3 4 5 6 7
/** * Returns index for hash code h. */ static int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); }
/** * Associates the specified value with the specified key in this map. * If the map previously contained a mapping for the key, the old * value is replaced. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt>. * (A <tt>null</tt> return can also indicate that the map * previously associated <tt>null</tt> with <tt>key</tt>.) */ public V put(K key, V value) { if (table == EMPTY_TABLE) { inflateTable(threshold); } if (key == null) return putForNullKey(value); int hash = hash(key); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } }
int capacity = 1; while (capacity < initialCapacity) capacity <<= 1;
threshold的值=容量*负载因子
看下roundUpToPowerOf2()
1 2 3 4 5 6
private static int roundUpToPowerOf2(int number) { // assert number >= 0 : "number must be non-negative"; return number >= MAXIMUM_CAPACITY ? MAXIMUM_CAPACITY : (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1; }
主要是Integer.highestOneBit
1 2 3 4 5 6 7 8 9
public static int highestOneBit(int i) { // HD, Figure 3-1 i |= (i >> 1); i |= (i >> 2); i |= (i >> 4); i |= (i >> 8); i |= (i >> 16); return i - (i >>> 1); }
/** * Offloaded version of put for null keys */ private V putForNullKey(V value) { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(0, null, value, 0); return null; }
这个逻辑比较简单
第一步,如果找到之前有key为null的key,进行一下value替换,返回oldValue
如果没有为null的key,那进行addEntry() 添加元素的主要方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
/** * Adds a new entry with the specified key, value and hash code to * the specified bucket. It is the responsibility of this * method to resize the table if appropriate. * * Subclass overrides this to alter the behavior of put method. */ void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); }
void createEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash; Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; }
/** * A randomizing value associated with this instance that is applied to * hash code of keys to make hash collisions harder to find. If 0 then * alternative hashing is disabled. */ transient int hashSeed = 0; /** * Initialize the hashing mask value. We defer initialization until we * really need it. */ final boolean initHashSeedAsNeeded(int capacity) { boolean currentAltHashing = hashSeed != 0; boolean useAltHashing = sun.misc.VM.isBooted() && (capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD); boolean switching = currentAltHashing ^ useAltHashing; if (switching) { hashSeed = useAltHashing ? sun.misc.Hashing.randomHashSeed(this) : 0; } return switching; }
The seed parameter is a means for you to randomize the hash function. You should provide the same seed value for all calls to the hashing function in the same application of the hashing function. However, each invocation of your application (assuming it is creating a new hash table) can use a different seed, e.g., a random value.
Why is it provided?
One reason is that attackers may use the properties of a hash function to construct a denial of service attack. They could do this by providing strings to your hash function that all hash to the same value destroying the performance of your hash table. But if you use a different seed for each run of your program, the set of strings the attackers must use changes.
private abstract class HashIterator<E> implements Iterator<E> { Entry<K,V> next; // next entry to return int expectedModCount; // For fast-fail int index; // current slot Entry<K,V> current; // current entry final Entry<K,V> nextEntry() { if (modCount != expectedModCount) throw new ConcurrentModificationException();
这个内部遍历类使用了Fail-Fast机制
1 2 3 4 5 6 7 8
/** * The number of times this HashMap has been structurally modified * Structural modifications are those that change the number of mappings in * the HashMap or otherwise modify its internal structure (e.g., * rehash). This field is used to make iterators on Collection-views of * the HashMap fail-fast. (See ConcurrentModificationException). */ transient int modCount;