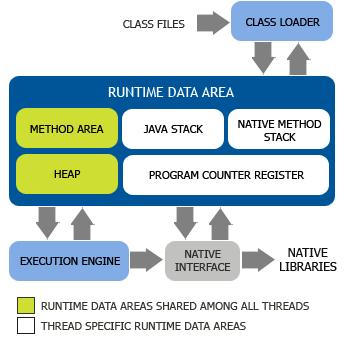
该类提供了线程局部 (thread-local)变量。 这些变量不同于它们的普通对应物,因为访问某个变量(通过其 get 或 set 方法)的每个线程都有自己的局部变量,它独立于变量的初始化副本。 ThreadLocal 实例通常是类中的 private static 字段,它们希望将状态与某一个线程(例如,用户 ID 或事务 ID)相关联。
public class HibernateUtil { private static Log log = LogFactory.getLog(HibernateUtil.class); private static final SessionFactory sessionFactory; //定义SessionFactory static { try { // 通过默认配置文件hibernate.cfg.xml创建SessionFactory sessionFactory = new Configuration().configure().buildSessionFactory(); } catch (Throwable ex) { log.error("初始化SessionFactory失败!", ex); throw new ExceptionInInitializerError(ex); } }
//创建线程局部变量session,用来保存Hibernate的Session public static final ThreadLocal session = new ThreadLocal(); /** * 获取当前线程中的Session * @return Session * @throws HibernateException */ public static Session currentSession() throws HibernateException { Session s = (Session) session.get(); // 如果Session还没有打开,则新开一个Session if (s == null) { s = sessionFactory.openSession(); session.set(s); //将新开的Session保存到线程局部变量中 } return s; } public static void closeSession() throws HibernateException { //获取线程局部变量,并强制转换为Session类型 Session s = (Session) session.get(); session.set(null); if (s != null) s.close(); } }
Threadlocal源码
这个类有以下方法:
get():返回当前线程拷贝的局部线程变量的值。
initialValue():返回当前线程赋予局部线程变量的初始值。
remove():移除当前线程赋予局部线程变量的值。
set(T value):为当前线程拷贝的局部线程变量设置一个特定的值。
get()方法
1 2 3 4 5 6 7 8 9 10
public T get() { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) { ThreadLocalMap.Entry e = map.getEntry(this); if (e != null) return (T)e.value; } return setInitialValue(); }
根据当前线程,拿到ThreadLocalMap,通过当前threadloal对象取到value.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
private T setInitialValue() { T value = initialValue(); Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); return value; } ThreadLocalMap getMap(Thread t) { return t.threadLocals; } void createMap(Thread t, T firstValue) { t.threadLocals = new ThreadLocalMap(this, firstValue); }
Thread.java 里面
ThreadLocalMap是Thread的属性
1 2 3
/* ThreadLocal values pertaining to this thread. This map is maintained * by the ThreadLocal class. */ ThreadLocal.ThreadLocalMap threadLocals = null;
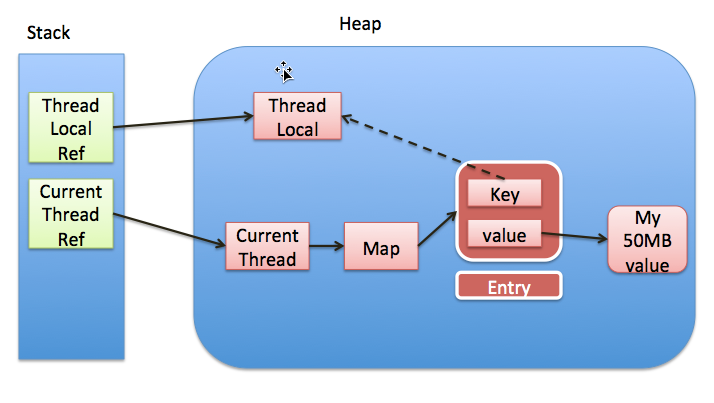
Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value
永远无法回收,造成内存泄露。
进一步分析一下ThreadlocalMap
1 2 3 4 5 6 7 8 9 10 11
/** * ThreadLocalMap is a customized hash map suitable only for * maintaining thread local values. No operations are exported * outside of the ThreadLocal class. The class is package private to * allow declaration of fields in class Thread. To help deal with * very large and long-lived usages, the hash table entries use * WeakReferences for keys. However, since reference queues are not * used, stale entries are guaranteed to be removed only when * the table starts running out of space. */ static class ThreadLocalMap {
/** * The entries in this hash map extend WeakReference, using * its main ref field as the key (which is always a * ThreadLocal object). Note that null keys (i.e. entry.get() * == null) mean that the key is no longer referenced, so the * entry can be expunged from table. Such entries are referred to * as "stale entries" in the code that follows. */ static class Entry extends WeakReference<ThreadLocal> { /** The value associated with this ThreadLocal. */ Object value;
/** * Construct a new map initially containing (firstKey, firstValue). * ThreadLocalMaps are constructed lazily, so we only create * one when we have at least one entry to put in it. */ ThreadLocalMap(ThreadLocal firstKey, Object firstValue) { //默认16长度 table = new Entry[INITIAL_CAPACITY]; //hashcode取模,得到坑位 int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); table[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY); }
/** * Set the resize threshold to maintain at worst a 2/3 load factor. */ private void setThreshold(int len) { threshold = len * 2 / 3; }
private void set(ThreadLocal key, Object value) {
// We don't use a fast path as with get() because it is at // least as common to use set() to create new entries as // it is to replace existing ones, in which case, a fast // path would fail more often than not. Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode & (len - 1);
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { ThreadLocal k = e.get();
tab[i] = new Entry(key, value); int sz = ++size; if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash(); } private void replaceStaleEntry(ThreadLocal key, Object value, int staleSlot) { Entry[] tab = table; int len = tab.length; Entry e;
// Back up to check for prior stale entry in current run. // We clean out whole runs at a time to avoid continual // incremental rehashing due to garbage collector freeing // up refs in bunches (i.e., whenever the collector runs). int slotToExpunge = staleSlot; //替换掉之前有key=null的 for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len)) if (e.get() == null) slotToExpunge = i;
// Find either the key or trailing null slot of run, whichever // occurs first for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal k = e.get();
// If we find key, then we need to swap it // with the stale entry to maintain hash table order. // The newly stale slot, or any other stale slot // encountered above it, can then be sent to expungeStaleEntry // to remove or rehash all of the other entries in run. if (k == key) { e.value = value;
tab[i] = tab[staleSlot]; tab[staleSlot] = e;
// Start expunge at preceding stale entry if it exists if (slotToExpunge == staleSlot) slotToExpunge = i; cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); return; }
// If we didn't find stale entry on backward scan, the // first stale entry seen while scanning for key is the // first still present in the run. if (k == null && slotToExpunge == staleSlot) slotToExpunge = i; }
// If key not found, put new entry in stale slot tab[staleSlot].value = null; tab[staleSlot] = new Entry(key, value);
// If there are any other stale entries in run, expunge them if (slotToExpunge != staleSlot) cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); }
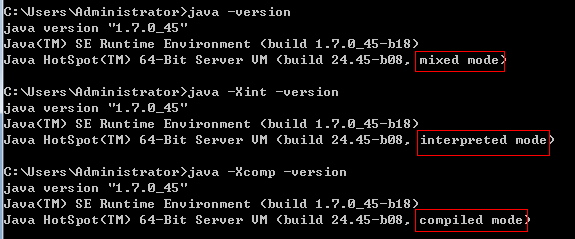
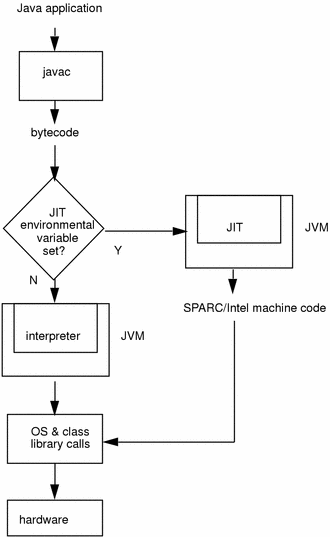
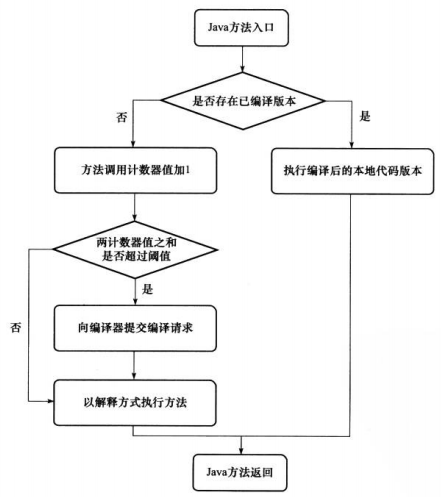
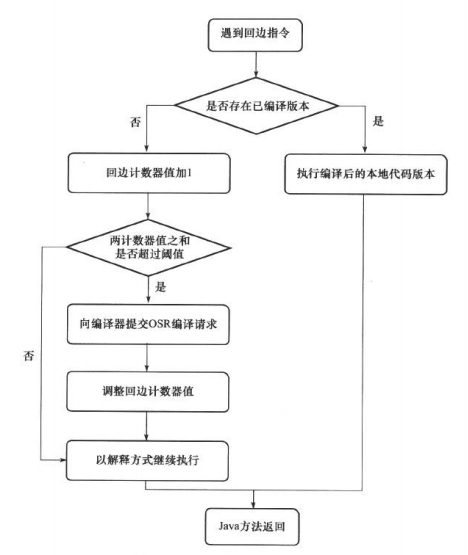
public class Pi { public static double calcPi() { double re = 0; for (int i = 1; i < 100000; i++) { re += ((i & 1) == 0 ? -1 : 1) * 1.0 / (2 * i - 1); } return re * 4; }
public static void main(String[] args) { long b = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) calcPi(); long e = System.currentTimeMillis(); System.err.println("spend:" + (e - b) + "ms"); } } mixed:spend:418ms int:spend:2547ms comp:spend:416ms
$ java -server -XX:+CITime Benchmark [...] Accumulated compiler times (for compiled methods only) ------------------------------------------------ Total compilation time : 0.178 s Standard compilation : 0.129 s, Average : 0.004 On stack replacement : 0.049 s, Average : 0.024 [...]
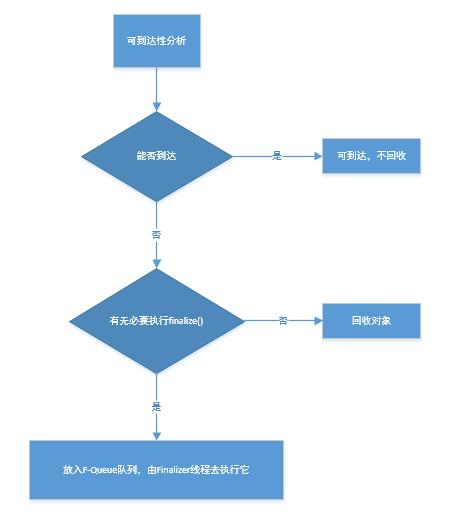
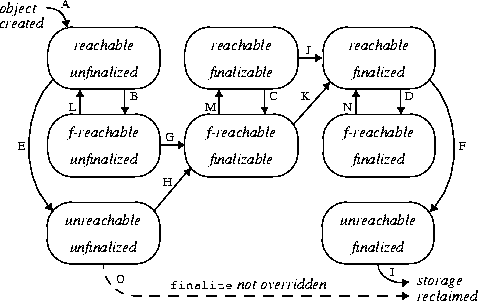
在某个时刻,JVM取出某个finalizable对象,将其标记为finalized并在某个线程中执行其finalize方法。由于是在活动线程中引用了该对象,该对象将变迁到(reachable, finalized)状态(K或J)。该动作将影响某些其他对象从f-reachable状态重新回到reachable状态(L, M, N), 这就是对象重生
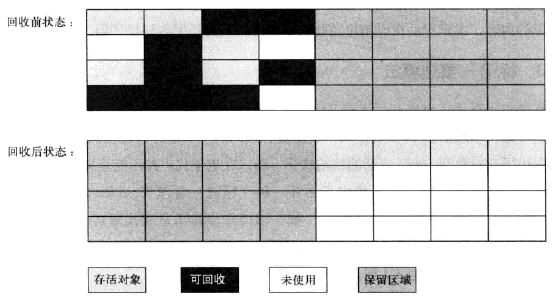
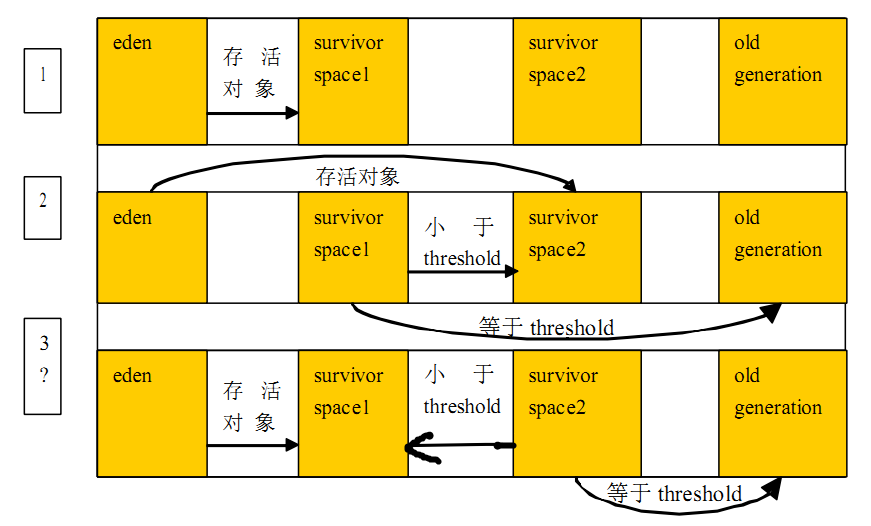
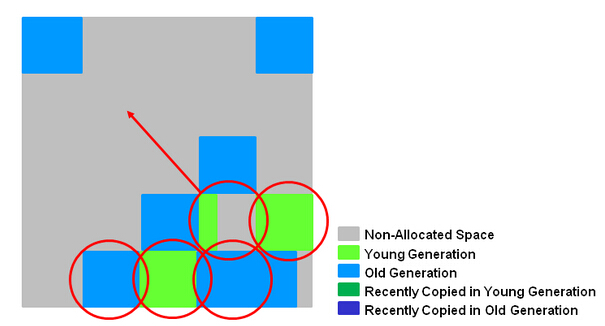
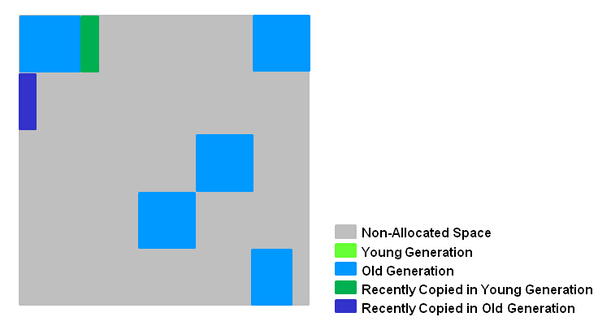
The reason for the HotSpot JVM’s two survivor spaces is to reduce the need to deal with fragmentation. New objects are allocated in eden space. All well and good. When that’s full, you need a GC, so kill stale objects and move live ones to a survivor space, where they can mature for a while before being promoted to the old generation. Still good so far. The next time we run out of eden space, though, we have a conundrum. The next GC comes along and clears out some space in both eden and our survivor space, but the spaces aren’t contiguous. So is it better to
Try to fit the survivors from eden into the holes in the survivor space that were cleared by the GC?
Shift all the objects in the survivor space down to eliminate the fragmentation, and then move the survivors into it?
Just say “screw it, we’re moving everything around anyway,” and copy all of the survivors from both spaces into a completely separate space–the second survivor space–thus leaving you with a clean eden and survivor space where you can repeat the sequence on the next GC?
Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory at java.nio.Bits.reserveMemory(Bits.java:658) at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123) at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:306) at com.stevex.app.nio.DirectByteBufferTest.main(DirectByteBufferTest.java:8)
public synchronized void export() { if (exported.get()) { LoggerUtil.warn(String.format("%s has already been expoted, so ignore the export request!", interfaceClass.getName())); return; }
// don't need to notifylisteners, because onSuccess or // onFailure or cancel method already call notifylisteners return getValueOrThrowable(); } else { long waitTime = timeout - (System.currentTimeMillis() - createTime);
if (waitTime > 0) { for (;;) { try { lock.wait(waitTime); } catch (InterruptedException e) { }
pipeline.addLast("handler", new NettyChannelHandler(NettyClient.this, new MessageHandler() { @Override public Object handle(Channel channel, Object message) { //得到返回对象 Response response = (Response) message; //得到对应request的future NettyResponseFuture responseFuture = NettyClient.this.removeCallback(response.getRequestId());
if (responseFuture == null) { LoggerUtil.warn( "NettyClient has response from server, but resonseFuture not exist, requestId={}", response.getRequestId()); return null; }
What is the difference between Service Provider Interface (SPI) and Application Programming Interface (API)? More specifically, for Java libraries, what makes them an API and/or SPI? the API is the description of classes/interfaces/methods/... that you call and use to achieve a goal the SPI is the description of classes/interfaces/methods/... that you extend and implement to achieve a goal Put differently, the API tells you what a specific class/method does for you and the SPI tells you what you must do to conform. Sometimes SPI and API overlap. For example in JDBC the Driver class is part of the SPI: If you simply want to use JDBC, you don't need to use it directly, but everyone who implements a JDBC driver must implement that class. The Connection interface on the other hand is both SPI and API: You use it routinely when you use a JDBC driver and it needs to be implemented by the developer of the JDBC driver。
JDK spi
使用jdk自带的ServiceLoader写一个示例:
一个接口
1 2 3 4
public interface Spi {
public void provide(); }
一个实现类
1 2 3 4 5 6 7
public class DefaultSpi implements Spi{
@Override public void provide() { System.out.println("默认spi实现"); } }
入口类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/** * 一个spi的demo * */ public class SpiDemoMain { public static void main( String[] args ) { ServiceLoader<Spi> spiServiceLoader = ServiceLoader.load(Spi.class);