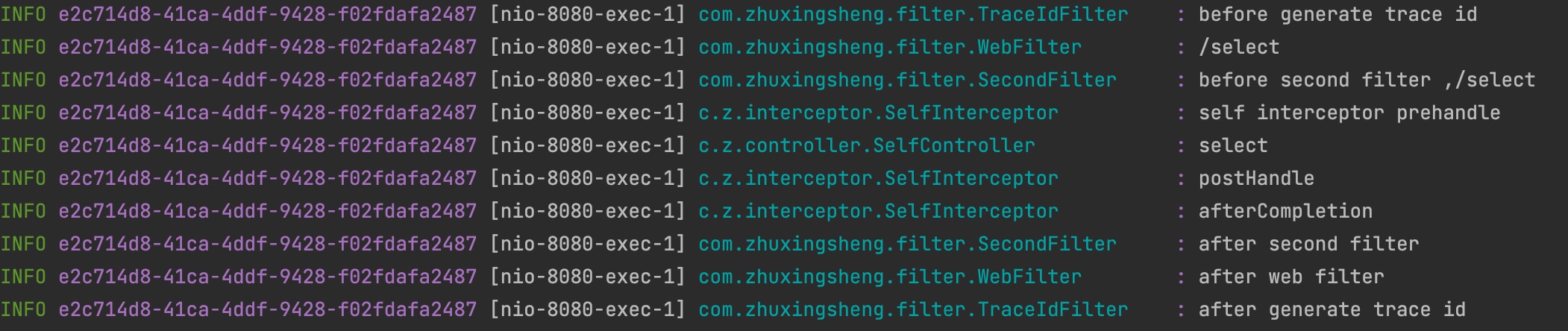
最近项目中使用了高版本的springboot-2.6.4,以及swagger3
1 | <dependency> |
结果启动应用程序失败,报错:
1 | Failed to start bean 'documentationPluginsBootstrapper'; nested exception is java.lang.NullPointerException |
这个问题,网上资料不少,主要原因是因为springboot2.6.x后,把pathMatcher默认值修改了,springfox年久失修,与springboot出现了兼容性问题。
找到一个Spring Boot下的Issue:https://github.com/spring-projects/spring-boot/issues/28794,但这个issue已经关闭了,目前这个问题的主要讨论在springfox,具体issue是这个:https://github.com/springfox/springfox/issues/3462
主要项目中还需要使用springboot-actuator,所以简单的修改一下配置spring.mvc.pathmatch.matching-strategy=ant-path-matcher还不行。可参考:Spring Boot 2.6.x 集成swagger3.0.0报错解决方案,Swagger is not working with Spring Boot 2.6.X
在此问题追踪过程中,第一个就是原先的Ant方式与当前的PathPattern有什么区别:
AntPathMatcher vs PathPattern
诞生时间
AntPathMatcher是一个早在2003年(Spring的第一个版本)就已存在的路径匹配器,
而PathPattern是Spring 5新增的,旨在用于替换掉较为“古老”的AntPathMatcher。
性能
PathPattern性能比AntPathMatcher优秀。
理论上pattern越复杂,PathPattern的优势越明显
功能
1、PathPattern只适用于web环境,AntPathMatcher可用于非web环境。
2、PathPattern去掉了Ant字样,但保持了很好的向下兼容性。
3、除了不支持将 ** 写在path中间之外(以消除歧义),其它的匹配规则从行为上均保持和AntPathMatcher一致
4、并且还新增了强大的{*pathVariable}的支持
1 | @Test |
在没有PathPattern之前,虽然也可以通过/**来匹配成功,但却无法得到匹配到的值,现在可以了!
5、整体上可认为后者兼容了前者的功能
具体介绍可查看:
《Spring5新宠PathPattern,AntPathMatcher:那我走?》
在源码中也有详细说明:
1 | org.springframework.web.util.pattern.PathPattern |
在springboot 2.6后,Spring MVC处理程序映射匹配请求路径的默认策略已从AntPathMatcher更改为PathPatternParser
Actuator端点现在也使用基于 PathPattern 的 URL 匹配。需要注意的是,Actuator端点的路径匹配策略无法通过配置属性进行配置。
如果需要将默认切换回 AntPathMatcher,可以将 spring.mvc.pathmatch.matching-strategy 设置为 ant-path-matcher
1 | spring.mvc.pathmatch.matching-strategy=ant-path-matcher |
springboot2.6.X与swagger3兼容
为什么改变了下pathmatch方式,就会影响到swagger,没想明白,毕竟swagger的路径,PathPattern也是可以正常解析的。
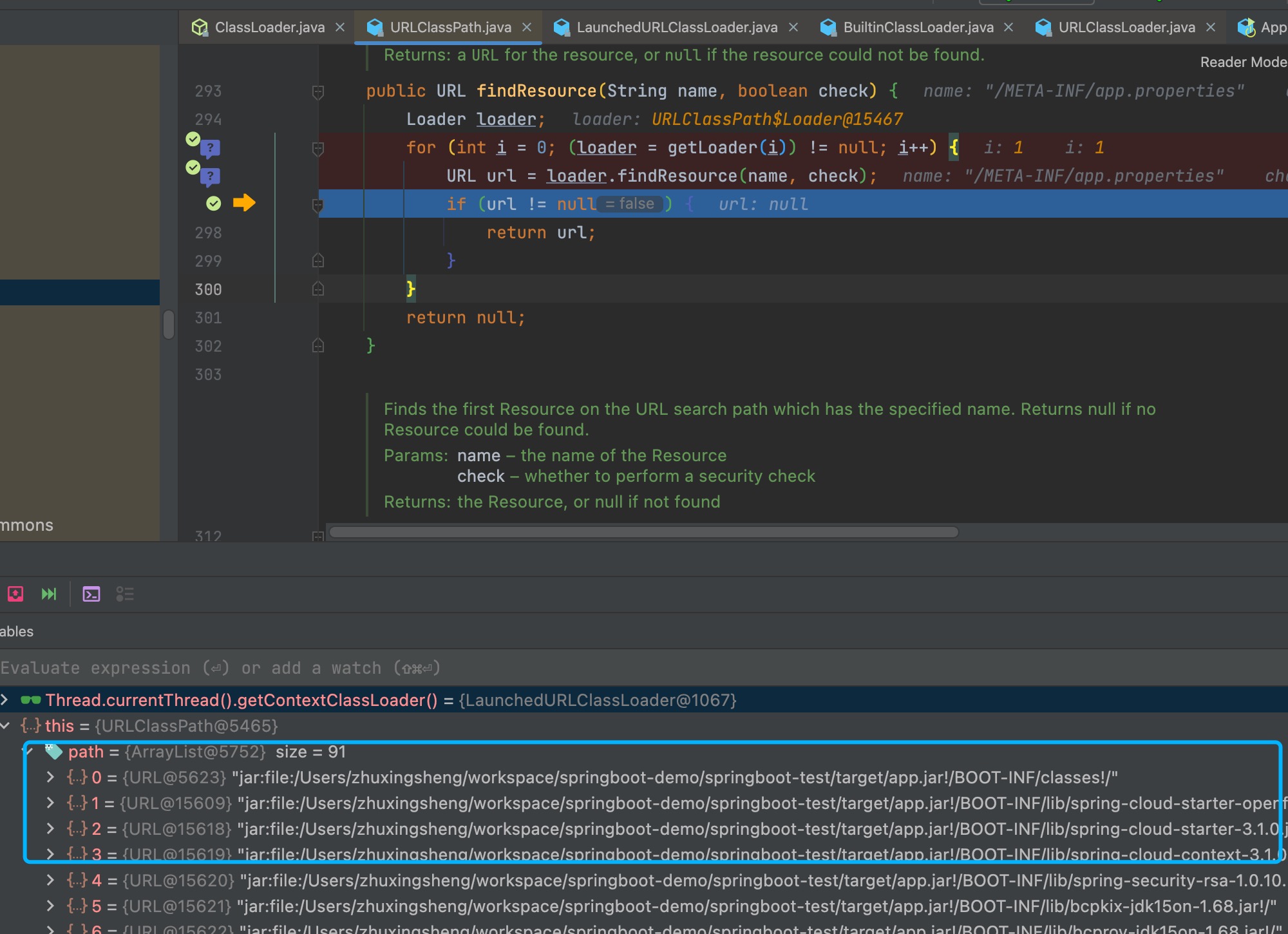
debug了下代码:
不配置spring.mvc.pathmatch.matching-strategy
应用在启动时,会自动设置PatternPaser
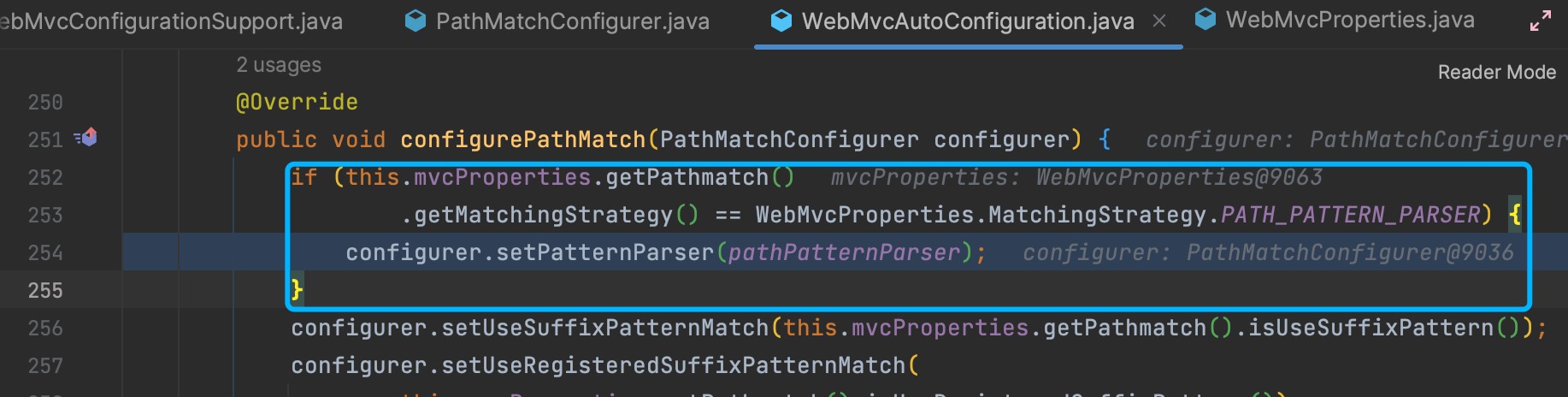
可以看到默认值就是PATH_PATTERN_PARSER,也正是springboot2.6后的默认方式:

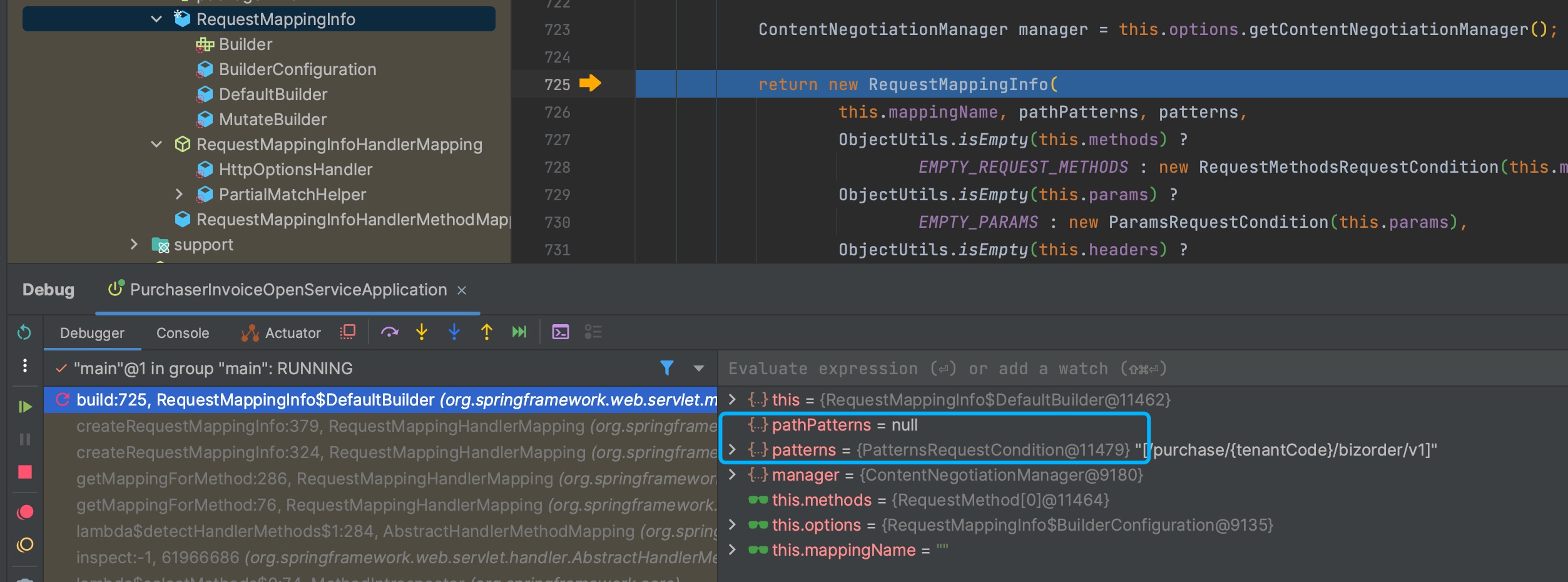
不配置时spring.mvc.pathmatch.matching-strategy,pathPatterns是被赋值的:
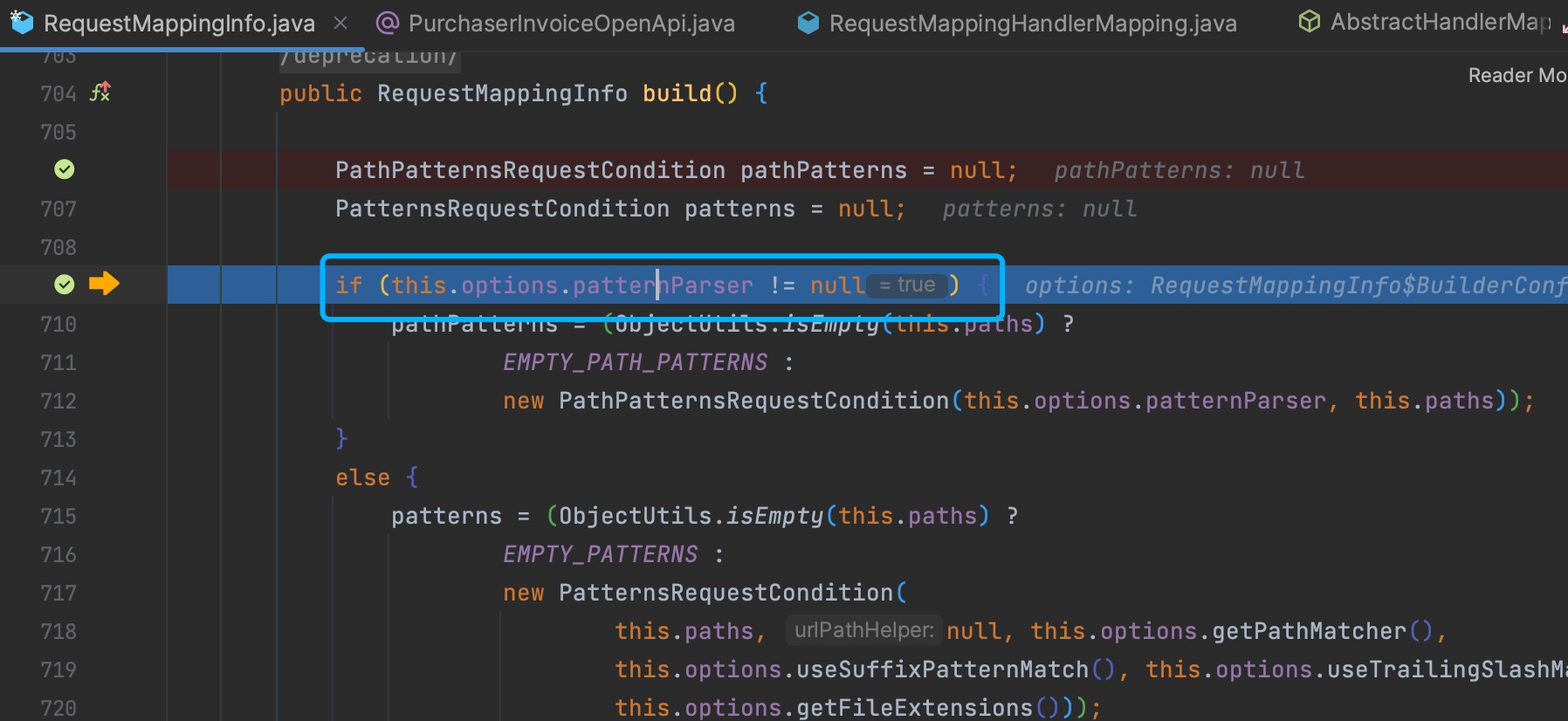
springfox.documentation.spring.web.WebMvcRequestHandler#getPatternsCondition时,就是null。
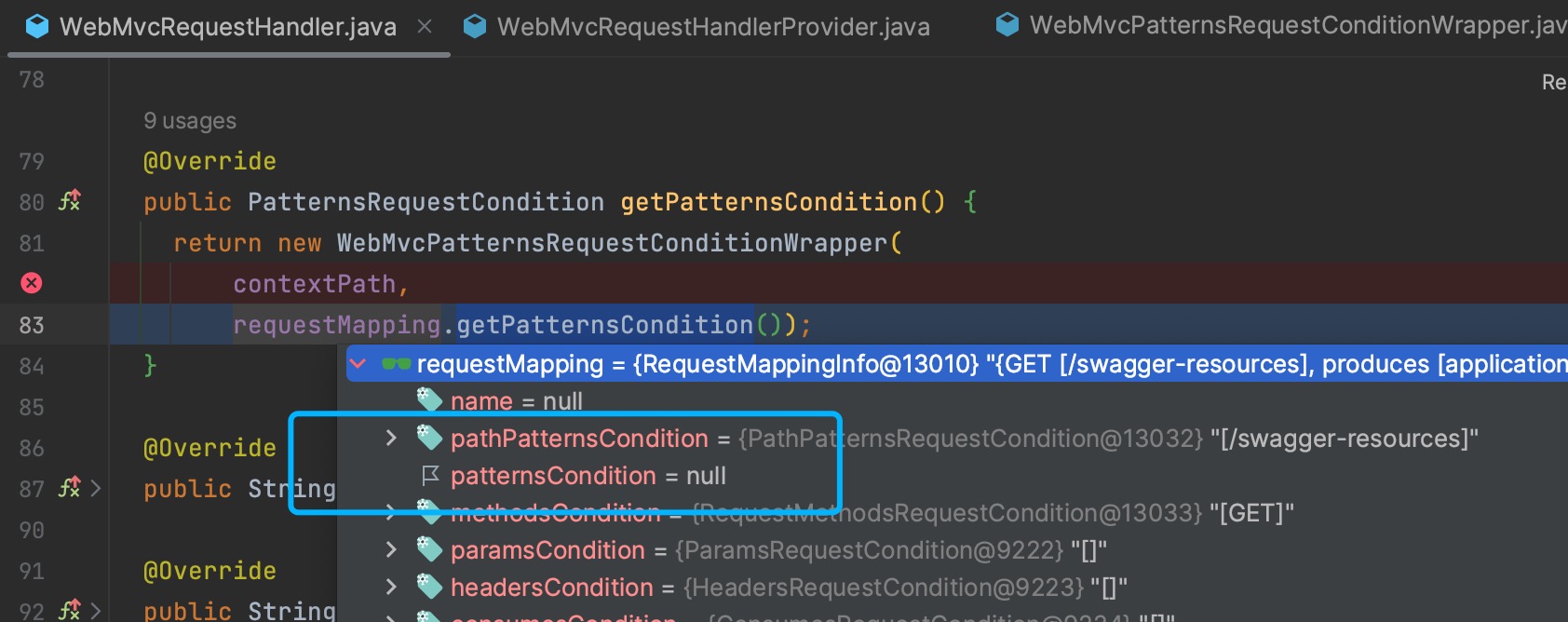
这样也就出现了文章开头的兼容问题。
在配置ant-path-matcher后,RequestMappingInfo中的pathPatterns和patterns的赋值变化,pathPatterns是无值,patterns是有值。
1 | spring.mvc.pathmatch.matching-strategy=ant-path-matcher |
解决方案
解决springboot2.6和swagger冲突的问题这篇文章算是列举方案比较全的。
如果只是通过BeanProcessor修改了HandleMapping,但不修改pathmatch,会访问不了swagger,会出现以下错误:
1 | o.s.web.servlet.PageNotFound : No mapping for GET /webjars/js/chunk-vendors.90e8ba20.js |
可以追加一下swagger资源的映射,最终出的方案:https://www.jianshu.com/p/1ea987c75073;
在整合actuator时,SpringBoot 2.6.* 整合springfox 3.0报错中也指出了,并且解释了原理。但没有理解作者表达的springfox.documentation.spring.web.WebMvcRequestHandler#getPatternsCondition时为null的过滤掉。
代码里面反而是把为null的提取出来了呀。
springdoc
既然swagger3.0更新不及时,就不用再纠结,直接使用springdoc也是很好的方案。
使用springdoc来替换swagger3.0,《从springfox迁移到springdoc》
总结
虽然解决了问题,但原理尚需追踪。不如用springdoc来得简单些。