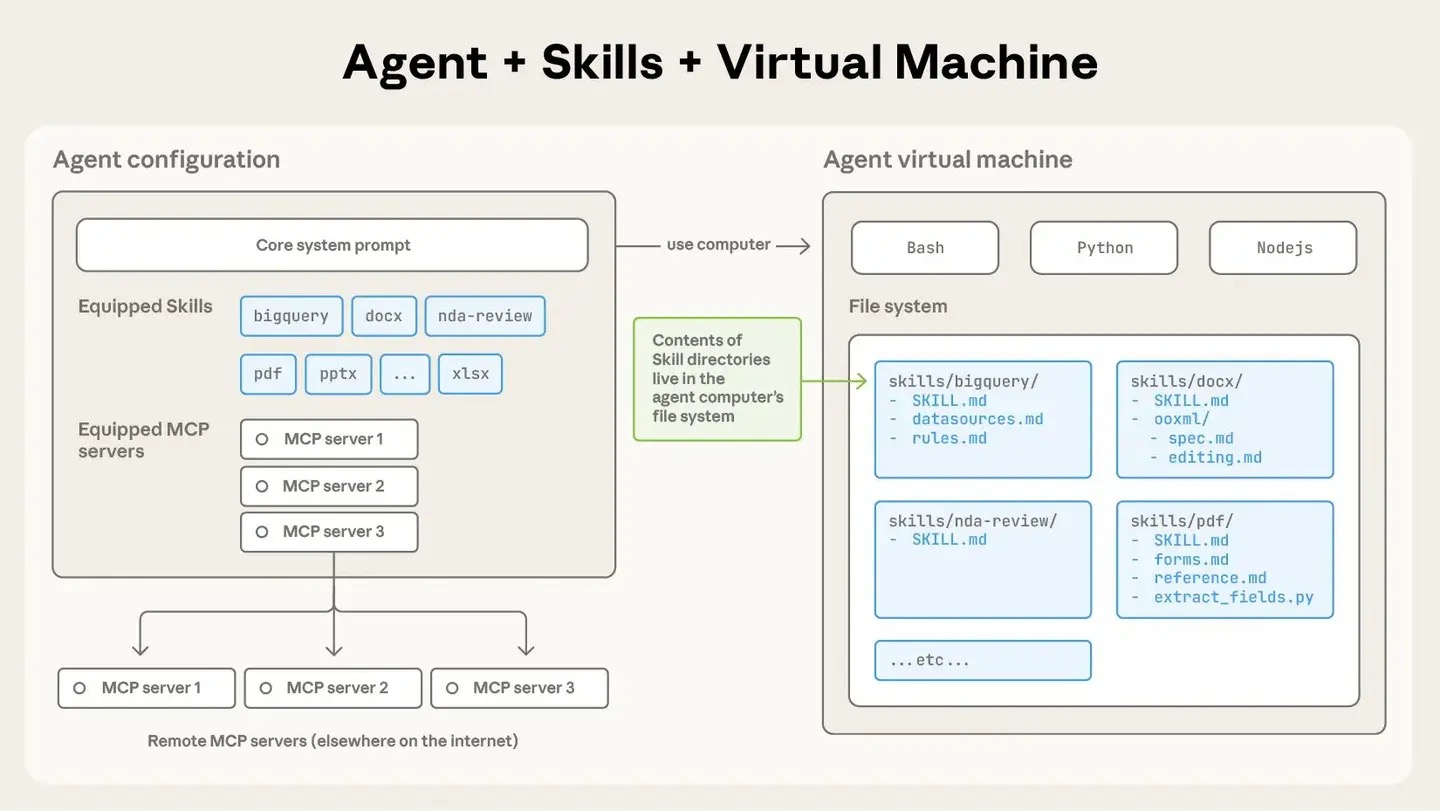
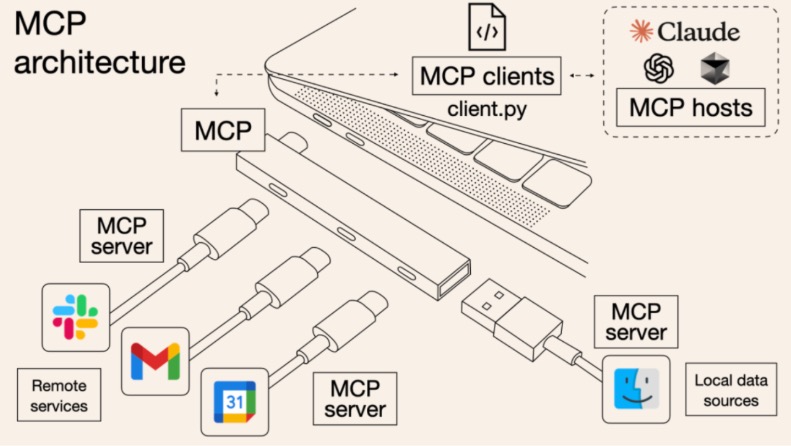
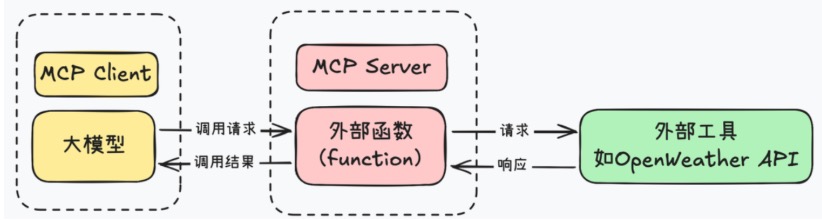
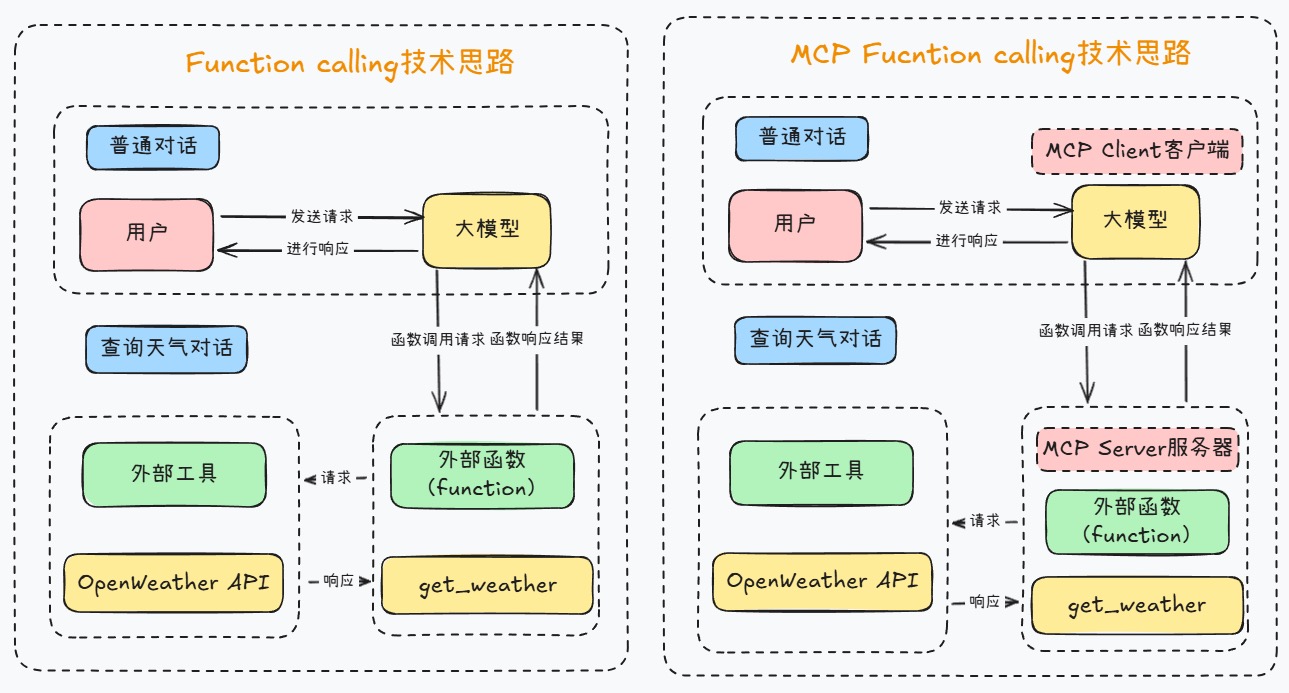
Harrison Chase(LangChain 联合创始人兼 CEO)那篇《How Coding Agents Are Reshaping Engineering, Product and Design》中文翻译:
编程Agent如何重塑工程、产品与设计
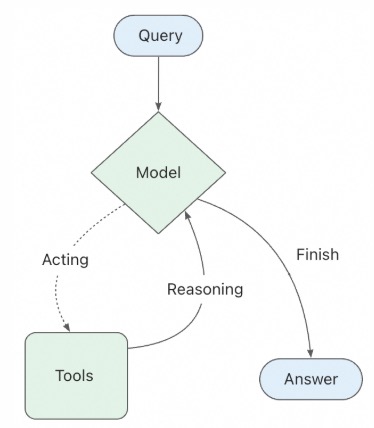
软件公司的 EPD(工程、产品与设计) 的核心是创建优秀的软件。虽然这些角色是分开的,但最终目标是产出能够解决商业问题、用户可用的功能性软件。归根结底,这一切都是代码。认识到 EPD 的产出本质上就是代码非常重要,因为……编程Agent突然让写代码变得非常容易。那么,这将如何改变 EPD 的角色呢?
流程的改变
1. PRD(产品需求文档)已死
在 Claude 时代之前,PRD 是软件开发的核心。EPD 的流程通常是这样的:
- 有人(通常是产品经理)有了一个想法
- 产品经理写一份 PRD
- 设计师根据 PRD 制作原型图
- 工程师将原型图转化为代码
想法 → PRD → 原型图 → 代码
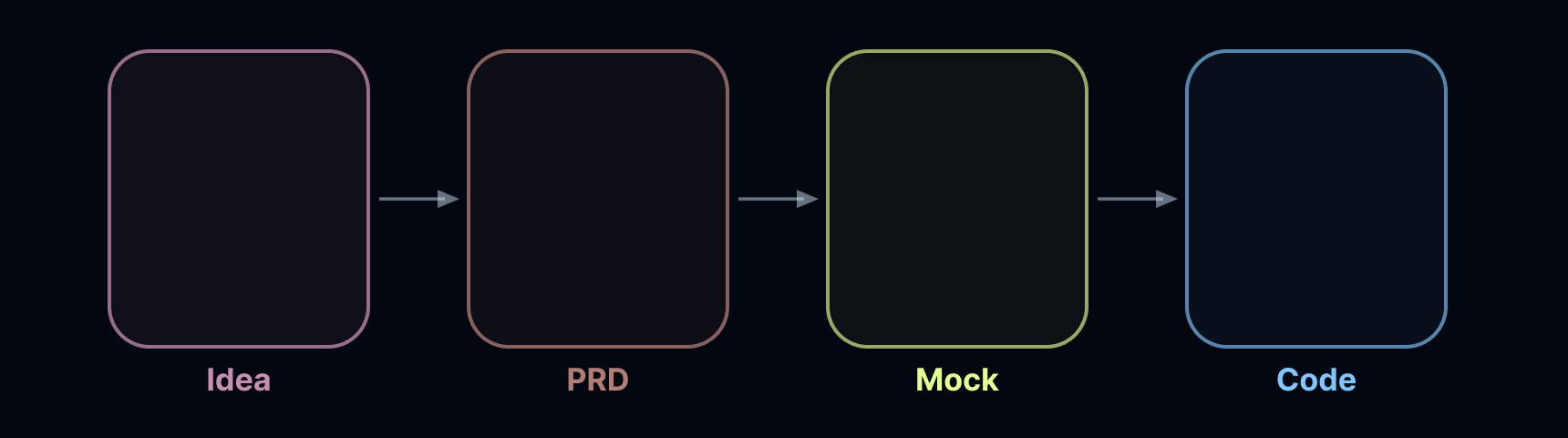
这并非硬性规定(在初创公司这些步骤是融合的,最好的构建者能同时做多项工作),但这是教科书式的开发方式。
之所以这样,是因为构建软件(和原型图)需要大量的时间和精力。因此,人们创造了专门的学科来处理这些工作。随着专业化程度提高,跨学科沟通的需求也随之产生。PRD 就是这一切的基础,它启动了整个流程。然后它像瀑布一样流向设计,设计师将漂亮的文字转化为漂亮的 UI 和流畅的 UX。最后工程师将其变为现实。
编程Agent改变了这一切。 编程Agent可以直接将一个想法转化为功能软件。当我说(以及其他人说)“PRD 已死”时,我们真正的意思是:这种从撰写 PRD 开始的传统软件构建方式已经终结了。
2. 瓶颈从“实施”转移到了“评审”
现在任何人都能写代码,这意味着任何人都能构建东西。但这并不意味着构建出来的东西架构良好、解决了正确的问题或者易于使用。工程、产品和设计应该成为这些领域的评审者和仲裁者。
问题是,生成的代码并不总是“优秀”的。EPD 的角色变成了评审并确保它是“优秀的”。“优秀”可以指代几层含义:
- 工程系统视角: 架构是否可扩展、高性能且稳健?
- 产品视角: 这是否解决了用户的痛点?
- 设计视角: 界面是否易于使用且直观?
由于创建初始版本代码的成本极低,我们看到产生了更多的原型。这些原型成为焦点,由产品、工程和设计进行评审。
想法 → 代码 → [产品反馈 / 工程反馈 / 设计反馈]
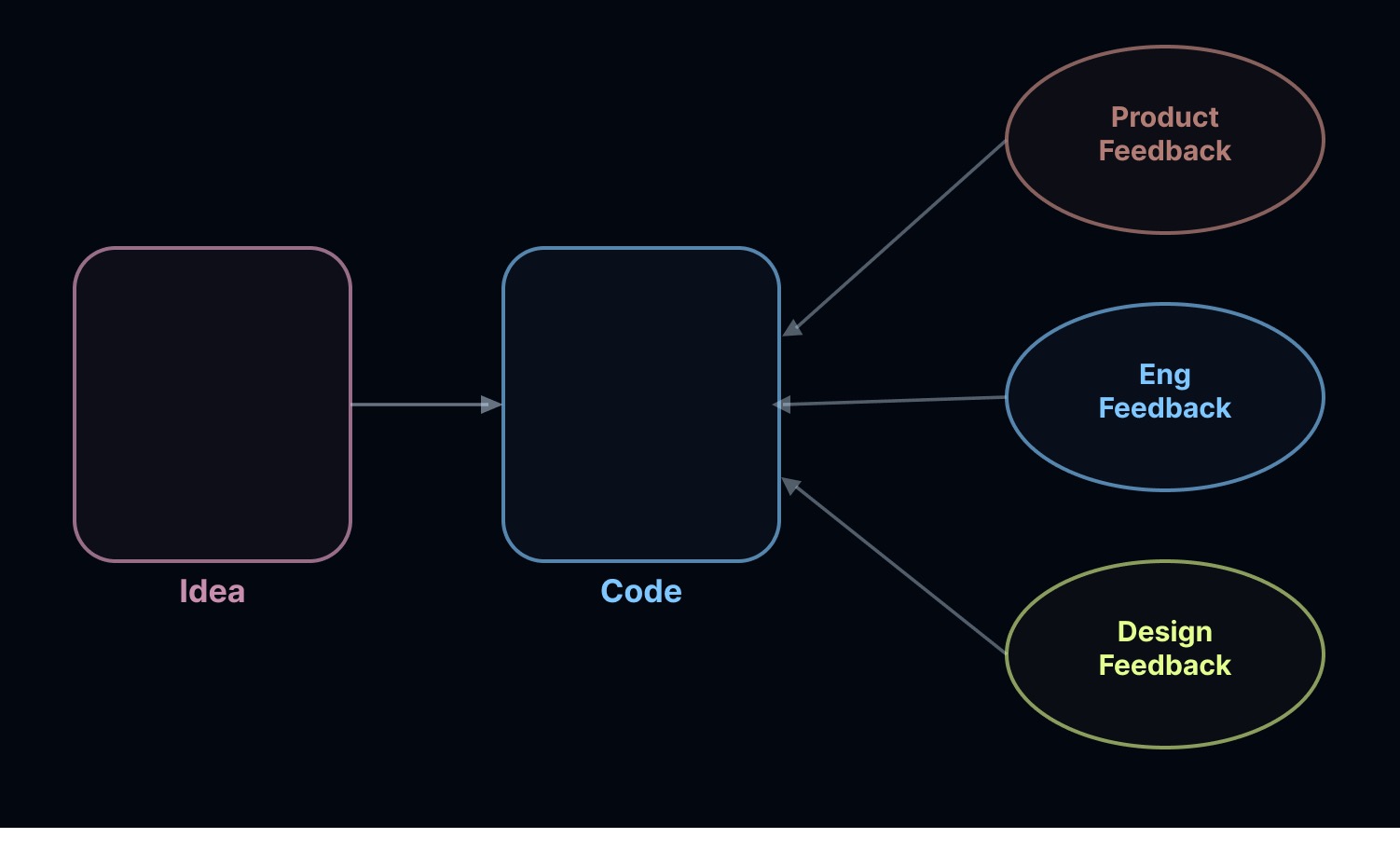
问题是——生成代码太容易了。以前,创建代码需要很长时间,所以作为评审者,你桌面上待审的项目数量有限。但现在——任何人都能写代码。这意味着正在进行的项目数量在增加。我们发现瓶颈(在所有三个职能中)在于评审——即拿走这些原型并确保它们是“好”的。
3. PRD 万岁
Claude 时代之前的软件构建方式(从 PRD 开始)已经过去。但描述产品需求的文档仍然是必不可少的。
假设有人有一个想法并快速构建了一个原型。如何将其投入生产?它需要经过 EPD 的其他成员评审。在这个过程中,书面文档总是有帮助的,而且往往是必要的。当其他人进行评审时,他们怎么知道代码的某一部分是偶然存在的还是有意为之的?这取决于意图。需要某种形式的意图沟通。
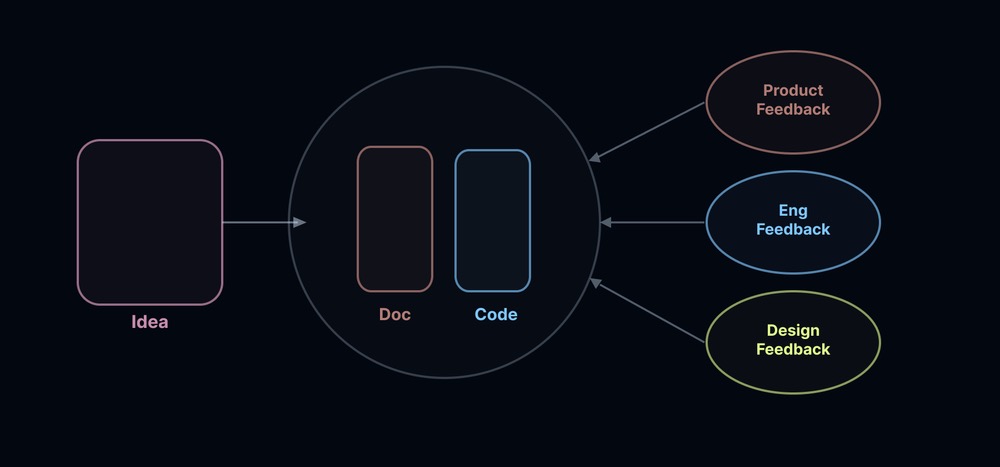
我认为传统的 PRD 流程(PRD → 原型图 → 代码)已经死了。但描述产品需求的文本还活着。这份相关文档应该是原型的必备伴侣,在移交评审之前必须存在。最标准的格式是文档,但也有一些关于共享创建此功能所用提示词(Prompts)的有趣想法。如果未来的 PRD 只是结构化的、版本化的提示词呢?
想法 → 文档 → 代码 → [产品反馈 / 工程反馈 / 设计反馈]
对角色的影响
1. 通才比以往任何时候都更有价值
我说的通才,是指对产品、工程和设计都有良好感知的人。这些人一直都很有价值且有影响力——但在编程Agent时代,他们更是如此。为什么?
沟通是一切中最难的部分。它会拖慢进度。 一个能同时做产品、设计和工程的人,会比一个三人的团队跑得更快,因为没有沟通开销。
以前,当实施是阻碍时,这个通才仍然需要与他人沟通才能完成工作。现在他们只需要与Agent沟通。这意味着他们仅凭自己就能产生比以往任何时候都大得多的影响力。
2. 编程Agent是刚需
随着编程Agent让实施变得廉价,使用它们成为了一种要求。能够采用编程Agent的人将能凭一己之力做更多的事:
- 产品经理: 采用编程Agent可以直接通过构建原型来验证想法,而无需撰写规格说明书和等待。
- 设计师: 采用编程Agent可以在代码中迭代,而不仅仅是在 Figma 中。
- 工程师: 采用编程Agent可以将时间从实施转移到系统思考。
采用编程Agent是刚需,因为这并不难,如果你不这样做,你就会被使用它的人取代。
3. 好的产品经理很棒,糟糕的产品经理很可怕
好的产品思维比以往任何时候都更有价值——你可以构建有用的东西。糟糕的产品思维比以往任何时候都更浪费。如果有人有一个糟糕的产品想法,他们可以带着一个原型出现——但这个原型将是一个无用或构思拙劣的功能。这些原型现在需要更多的评审——来自工程、产品和设计。这消耗了时间和资源。而且,将这些原型投入生产的惯性更大(“它已经存在了!我们就合并它吧!”)。这有制造出更差或臃肿产品的风险。
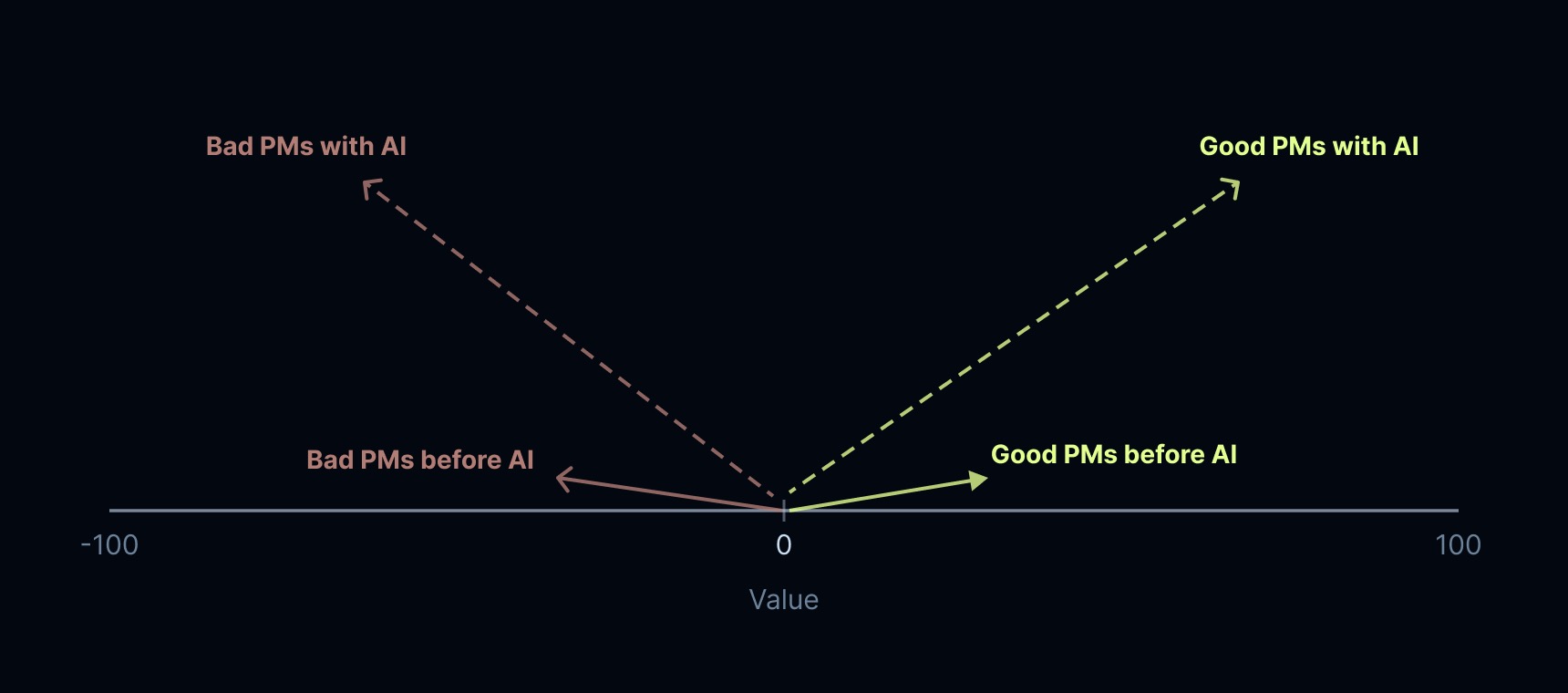
(此处原文有图表:糟糕的 PM 使用 AI 产生负价值,优秀的 PM 使用 AI 产生高价值)
4. 系统思考是需要磨练的技能
在一个执行廉价的世界里,系统思考成为了差异化因素。你应该专注于擅长系统思考,并对你特定的领域有清晰的心智模型:
- 工程: 对如何架构服务、API 和数据库有极佳的心智模型。
- 产品: 对用户真正需要什么(而不是他们说想要什么)有极佳的心智模型。
- 设计: 对为什么某些东西看起来和用起来感觉对劲有极佳的心智模型。
系统思考一直很重要——那么什么变了?实施成本大幅下降。 这意味着实施某件事比以往任何时候都容易——但这并不意味着它很棒。成为一个好的系统思考者可以让你确保你一开始就构建了正确的东西。它也让你在事后评审他人的工作。这两点都意味着成为好的系统思考者的重要性增加了。
5. 每个人都需要产品感
编程Agent仍然需要有人向它们发出提示。有人告诉它们做什么。如果你告诉它们构建错误的东西——你就是在为其他人制造更多需要评审的垃圾。知道告诉Agent构建什么(“产品感”)是必须的,否则你会成为组织的拖累。这在工程、设计和(显然的)产品中都是如此。
EPD 的很大一部分现在是评审原型。如果你有产品感,评审设计/工程会更容易。如果你没有产品感,你需要一份与原型并行的超级详细的产品文档。如果你有产品感,你只需要最小的规格说明书就能理解功能的意图,从而加速沟通、评审和交付。
6. 专业化的门槛变高了
你需要知道如何使用编程Agent。你需要产品感。所有角色都在融合。
角色之间一直存在重叠。设计和产品长期以来联系紧密——在苹果和 Airbnb 等公司,设计师充当产品经理。“设计工程师”作为一种角色在 Vercel 等公司越来越流行。
这并不意味着没有专业化的空间。一个只思考系统架构的资深工程师仍然很有价值。就像一个没有掌握“氛围编码”(vibe coding)但对客户问题和构建内容有超级清晰心智模型的 PM 一样。设计师也是如此,他们可以理解和模拟用户旅程和交互,即使仍在使用 Figma。
但专业化的门槛更高了。你不仅要精通你的领域,还要在评审上极快,并且是令人难以置信的沟通者。而且在任何给定的公司里,可能都没有那么多这些角色。
7. 你不是构建者,就是评审者
我们在 EPD 中看到了两种不同类型的角色正在出现。
第一:构建者(Builders)。 这种原型具有良好的产品思维,能够使用编程Agent,并具备基础的设计直觉。在一定的限制范围内(测试套件、组件库),他们可以将小型功能从想法推向生产,并为大型功能制作功能原型。
第二:评审者(Reviewers)。 对于大型和复杂的功能,需要详细的 EPD 评审。这对评审者的要求很高——你必须是你领域的杰出系统思考者。你还必须以快节奏工作——有太多东西需要评审。
如果你现在是一名工程师——你应该要么努力在系统设计上变得出色并习惯评审架构,立志成为一名评审者……要么尝试增长你的产品/设计技能并成为一名构建者。
如果你在产品或设计领域——你必须要么对产品/设计有极佳的心智模型并主要进行评审……要么跳进编程Agent并提高你的编码能力。
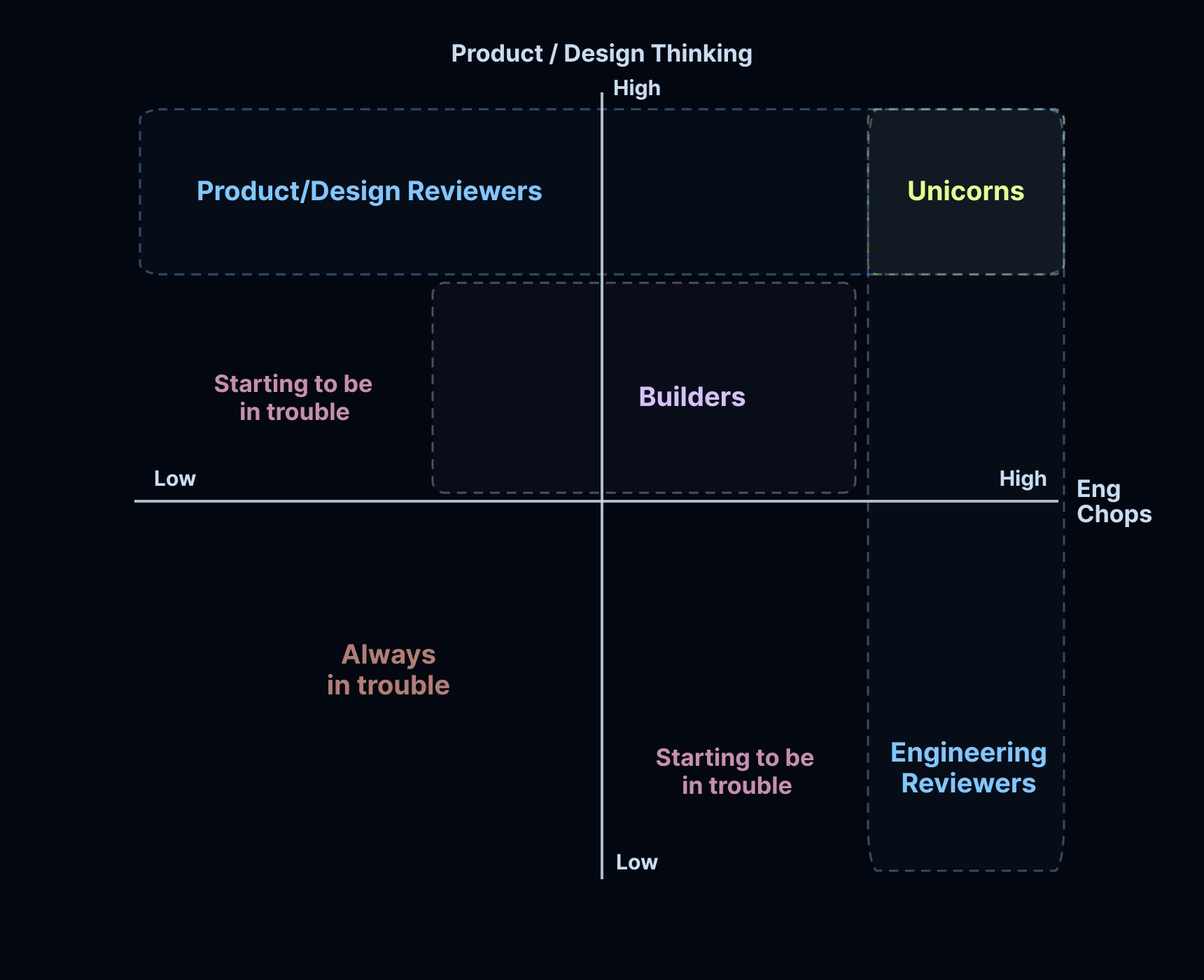
(此处原文有图表:横轴为工程能力,纵轴为产品/设计思维)
- 独角兽(Unicorns): 高工程能力 + 高产品/设计思维(构建者)
- 开始有麻烦的人: 低工程能力 + 高产品/设计思维(产品/设计评审者)
- 开始有麻烦的人: 高工程能力 + 低产品/设计思维(工程评审者)
- 总是有麻烦的人: 低工程能力 + 低产品/设计思维
有趣的是,角色正在某种程度上瓦解,如上图所示。角色开始融合——工程师有更多时间,可以更多地思考产品和设计。产品和设计可以创建代码。
8. 每个人都认为他们的角色从编程Agent中获益最大——而且他们是对的
Twitter 上有一篇关于从编程Agent中获益最大的人类型的精彩帖子:
“一个对现有产品有直观把握的人,知道它的软肋在哪里,哪里表现出色,以及如何将其迭代得更加锐利。
这种人的罕见版本存在于文化和深度技术的交界处。一个真正双语的人。他们知道技术上什么是可能的,也知道哪些文化潮流是真实的,哪些是短暂的。这种组合区分了那些感觉不可避免的产品和那些感觉是拼凑起来的产品。”
这篇文章很好地概括了这个新世界,它一度半病毒式传播。它之所以走红,是因为每个读到它的人都认为这是在说他们或他们的角色。我看到产品经理在引用它,设计师、设计工程师、创始人……每个人都认为它适用于他们和他们的角色。
而且他们可能都对!我认为这个新世界最令人兴奋的事情是,背景变得不那么重要了。我真心相信这种原型人物可能来自产品、设计或工程。这并不意味着每个人都会成为这种人——这说起来容易做起来难。真正的独角兽非常少。
这是一个令人兴奋的构建时代 :)