--- name: extend-mingli-shensha description: Add or update shensha logic in the mingli repo, including rule documentation, utility functions, explanation/method text, and UI display. Use when Codex needs to add a new 神煞, adjust an existing 神煞’s取法 or作用, wire it into src/utils/shensha.ts, update docs/shensha-*.md and docs/shensha-overview.md, or connect it to the App.tsx/App.css display and popup flow. ---
# Extend Mingli Shensha
Implement new shensha in this repo with the same pattern already used for 驿马、桃花、羊刃、禄、天乙贵人、三丘五墓.
## Quick workflow
1. Read `docs/shensha-overview.md` first. 2. If the target shensha already has a dedicated doc, read `docs/shensha-*.md`; otherwise create one before coding. 3. Implement or update logic in `src/utils/shensha.ts`. 4. If the shensha should appear in the UI, wire it into `src/App.tsx` and `src/App.css`. 5. If the shensha needs click-to-explain support, add explanation and method text in `src/utils/shensha.ts`. 6. Run `npm run build` before finishing.
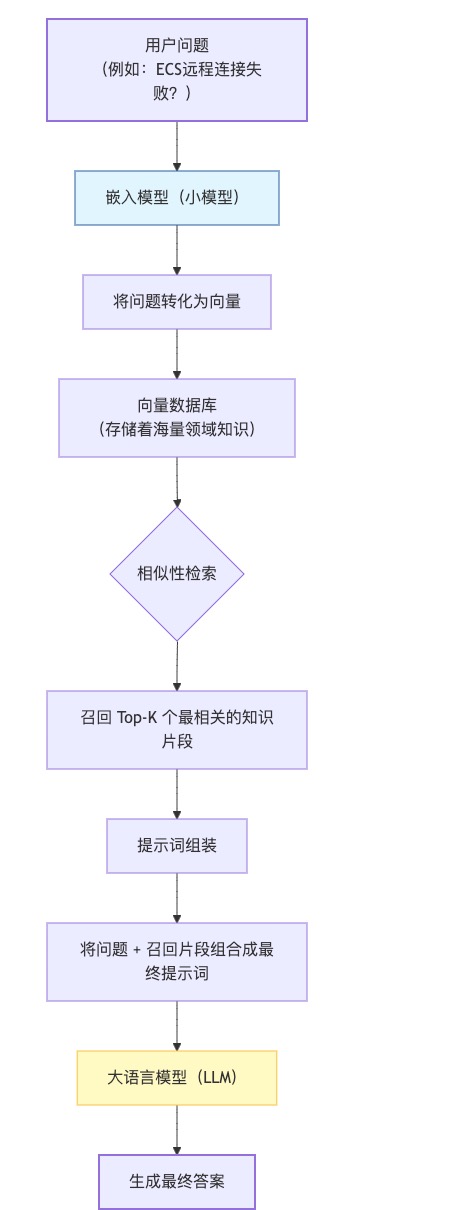
flowchart TD
A["用户问题 (例如:ECS远程连接失败?)"] --> B["嵌入模型 (小模型)"]
B --> C["将问题转化为 向量"]
C --> D["向量数据库 (存储着海量领域知识)"]
D --> E{"相似性检索"}
E --> F["召回 Top-K 个 最相关的知识片段"]
F --> G["提示词组装"]
G --> H["将问题 + 召回片段 组合成最终提示词"]
H --> I["大语言模型 (LLM)"]
I --> J["生成最终答案"]
style A stroke-width:2px
style B fill:#e1f5fe,stroke:#01579b
style I fill:#fff9c4,stroke:#fbc02d
style J stroke-width:2px