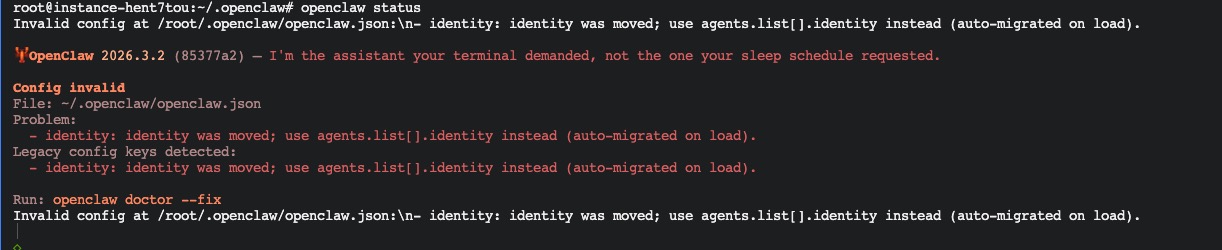
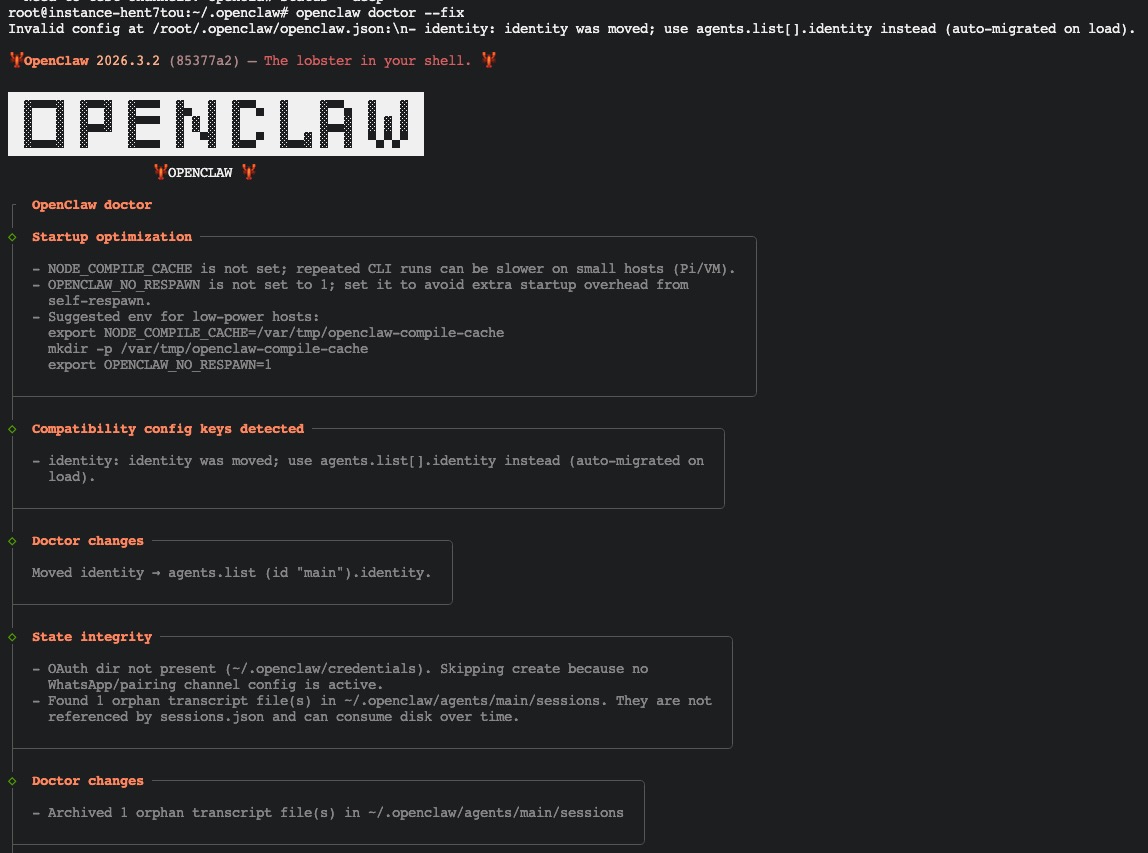
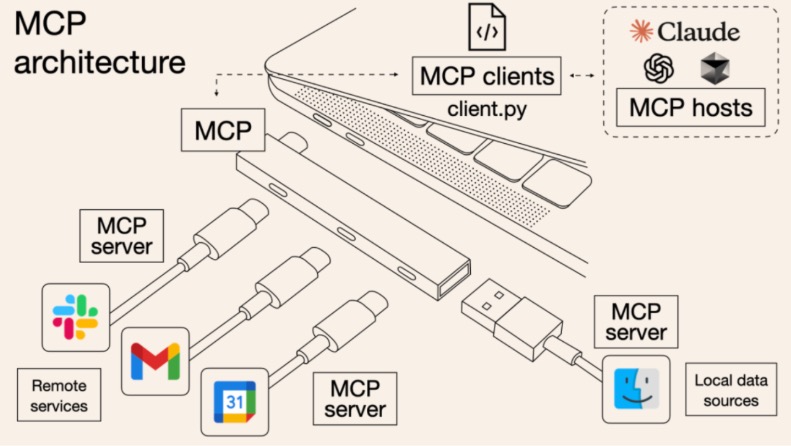
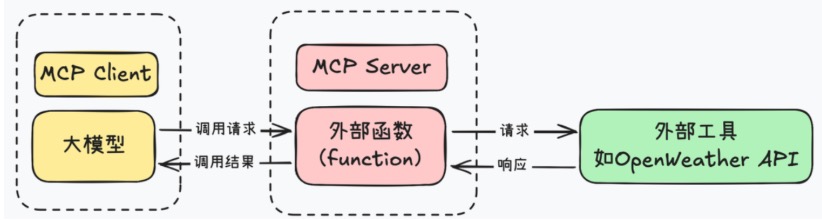
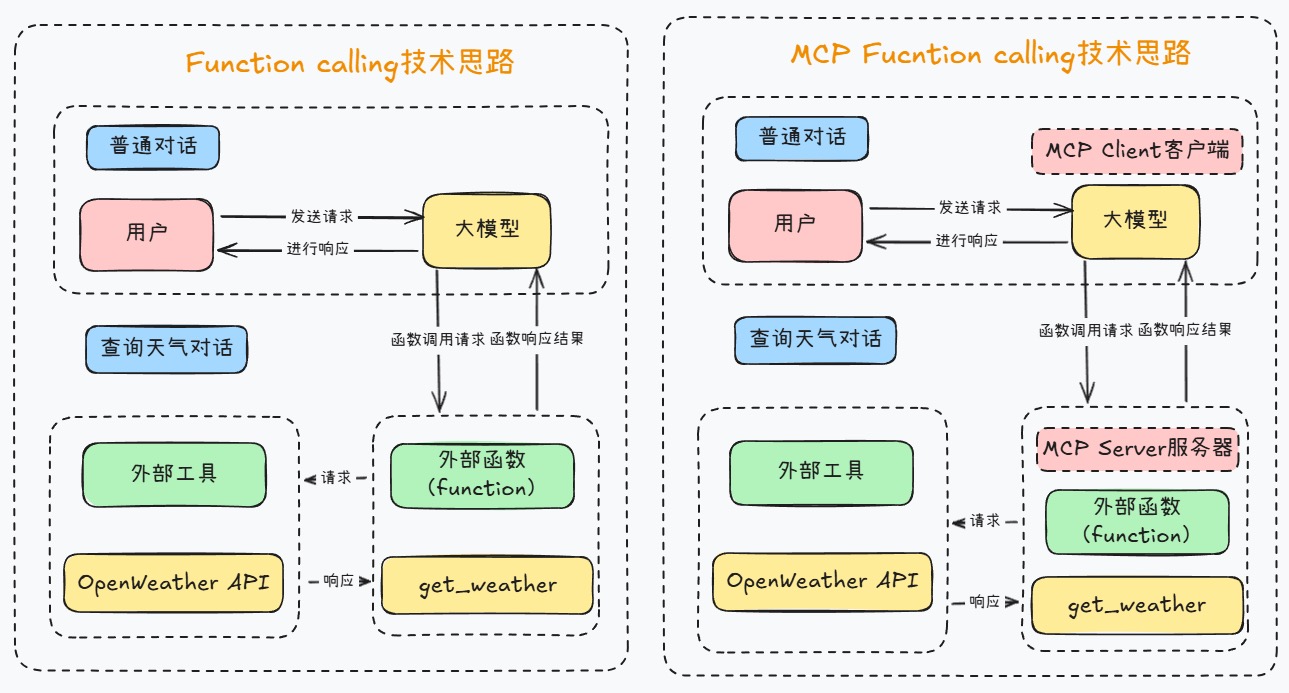
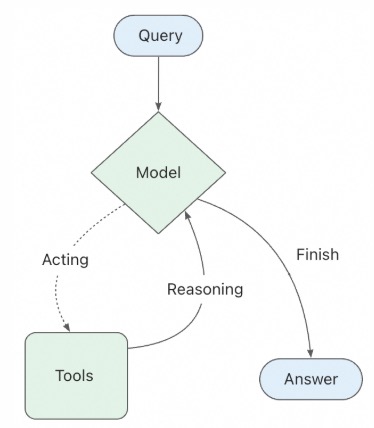
🔍 WHAT(是什么)
Skills 是一种应用层的架构模式,它将完成特定任务的专业知识、业务流程和最佳实践封装成可供 LLM 按需加载的”操作说明书”。
本质特征:
- 是一个结构化的 Markdown 文件(SKILL.md)+ 可选的脚本代码
- 是写给 LLM 看的 SOP(标准作业程序)
- 是可复用、可版本化、可共享的知识资产
- 不是 LLM 的原生能力,而是建立在 Function Calling 和 MCP 之上的上层建筑
文件结构示例:
1 | skill-name/ |
🎯 WHY(为什么需要)
七大核心价值:
| 维度 | 问题 | Skill 的解决方案 |
|---|---|---|
| 认知负担 | 上下文臃肿,LLM注意力分散 | 渐进式加载,只加载需要的内容 |
| 知识封装 | 隐性知识流失,每次都要重复说 | 将业务规则固化在SKILL.md中 |
| 执行质量 | 输出不稳定,错误处理差 | 预设流程和容错机制,确保一致性 |
| 成本效益 | Token浪费严重,响应慢 | 按需加载,节省50-80% token |
| 可维护性 | 提示词难以版本管理 | Git管理,团队协作,持续优化 |
| 安全合规 | 权限难以控制 | 应用层统一鉴权、审计 |
| 生态价值 | 知识无法交易传承 | 技能市场,知识资产化 |
一句话总结:Function Calling + MCP 解决了”怎么调用工具”的技术问题,而 Skill 解决了”如何让 AI 专业地工作”的系统问题。
👤 WHO(谁负责)
Skill 涉及三个角色,职责清晰分离:
| 角色 | 负责什么 | 核心能力 |
|---|---|---|
| 应用层(Agent框架) | 技能注册、权限控制、元数据注入、实际执行 | 确定性、安全性、管理性 |
| LLM | 理解元数据、匹配用户意图、选择技能、按指令执行 | 语义理解、推理决策 |
| 开发者/领域专家 | 编写 SKILL.md、开发脚本、定义业务规则 | 领域知识、工程实现 |
决策分工:
- 应用层负责:“有什么技能可用”(提供菜单)
- LLM 负责:“该用哪个技能”(根据菜单点菜)
- 开发者负责:“技能该怎么做”(写菜谱)
⏰ WHEN(何时使用)
适用场景:
| 场景类型 | 示例 | 是否需要用 Skill |
|---|---|---|
| 单次、简单任务 | 查天气、算算术 | ❌ Function Calling 足够 |
| 需要多步操作 | 生成财报、代码审查 | ✅ Skill 必备 |
| 有固定业务流程 | 请假审批、报销流程 | ✅ Skill 必备 |
| 包含业务规则 | 财务合规、医疗规范 | ✅ Skill 必备 |
| 需要稳定输出 | API 接口、报表生成 | ✅ Skill 必备 |
| 知识可复用 | 周报模板、会议纪要 | ✅ Skill 最佳 |
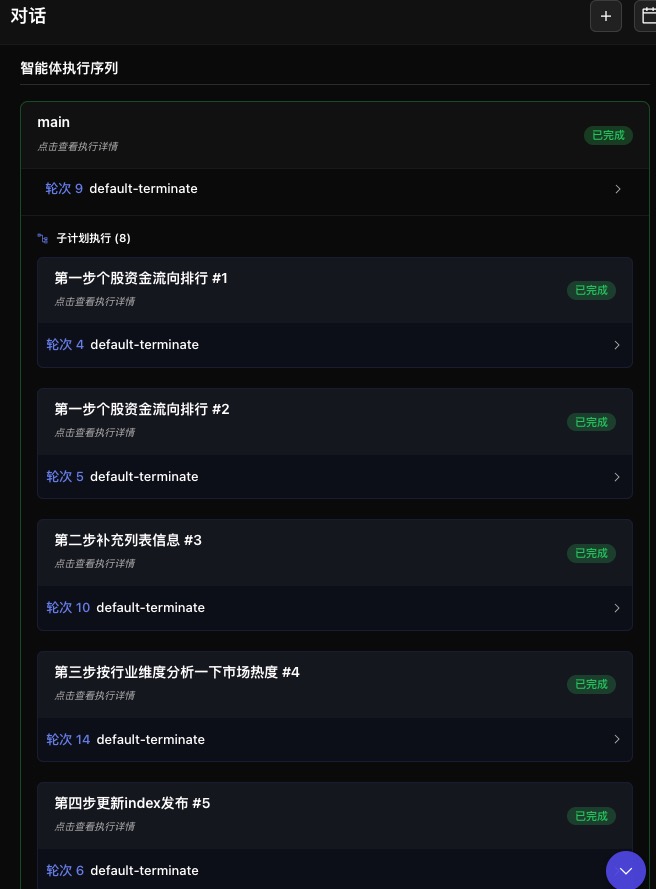
触发时机:当用户请求匹配到某个技能的 description 时,LLM 会调用 activate_skill 激活该技能。
📍 WHERE(在哪里运行)
Skill 的运行环境是分层的:
flowchart TB
subgraph Cloud[云端/本地]
A[应用层 - Skill Registry]
B[技能存储 - SKILL.md + scripts]
end
subgraph LLM[LLM 服务商]
C[LLM 推理引擎]
D[上下文 - 元数据 + 激活的指令]
end
subgraph Tools[工具层]
E[MCP 服务器]
F[外部 API/数据库]
end
A -- "注入元数据" --> C
C -- "activate_skill" --> A
A -- "提供工具描述" --> C
C -- "调用工具" --> E
E --> F
- 元数据:在 LLM 上下文中
- 完整指令:激活后加载到 LLM 上下文
- 脚本代码:在应用层执行(LLM 不加载)
- 工具调用:通过 MCP 标准化接入
🔧 HOW(如何工作)
5.1 核心机制:渐进式加载
| 阶段 | 加载内容 | Token 消耗 | 谁负责 |
|---|---|---|---|
| 1. 元数据层 | name + description | ~20 token/技能 | 应用层注入 |
| 2. 决策层 | 语义匹配,选择技能 | 推理计算 | LLM |
| 3. 激活层 | 返回 activate_skill 调用 |
结构化的 tool_calls | LLM |
| 4. 指令层 | 完整 SKILL.md | ~2000 token/技能 | 应用层加载 |
| 5. 执行层 | 按指令调用工具 | 按需加载工具描述 | LLM + 应用层 |
5.2 完整调用流程
sequenceDiagram
participant U as 用户
participant L as LLM
participant A as 应用层
participant T as 工具(MCP)
Note over L: 上下文有技能元数据列表
U->>L: "审查这段代码"
L->>L: 语义匹配,选择 code-reviewer
L->>A: 返回 tool_calls
{name:"activate_skill", args:{name:"code-reviewer"}}
A->>A: 验证权限,加载 SKILL.md
A-->>L: 注入完整技能指令
loop 按步骤执行
L->>A: 调用工具(Function Calling)
A->>T: 通过 MCP 执行
T-->>A: 返回结果
A-->>L: 注入结果
L->>L: 决定下一步
end
L-->>U: 返回最终结果
5.3 关键技术点
| 技术 | 在 Skill 中的作用 |
|---|---|
| Function Calling | LLM 调用 activate_skill 和具体工具 |
| MCP | 标准化接入各类工具 |
| 元数据注入 | 应用层告诉 LLM 有什么可用技能 |
| 语义匹配 | LLM 理解用户意图,选择合适技能 |
| 按需加载 | 只加载需要的指令和工具,节省上下文 |
📊 6.1 效果总结
| 指标 | 无 Skill | 有 Skill | 提升 |
|---|---|---|---|
| 上下文占用 | 50,000+ token | 10,000 token | 5倍节省 |
| 响应时间 | 3-5秒 | 1-2秒 | 2-3倍 |
| 成本 | $0.15/次 | $0.03/次 | 5倍节省 |
| 错误率 | 20% | 2% | 10倍提升 |
| 开发效率 | 2周/功能 | 2天/功能 | 5倍提升 |
🎯 终极总结
1 | # Skill 的 5W1H 一句话版 |
Skill 的本质:它是 Function Calling 和 MCP 之上的智能封装层,把 LLM 的灵活性(理解与决策)和应用层的确定性(流程与管控)完美结合,让 AI 真正成为能稳定处理复杂任务的”领域专家”。